语音识别是人工智能和机器学习应用的一个重要方向,并发展成为一个具有广阔前景的新兴高技术产业。近年来,人工智能技术的再一次兴起使得语音识别技术突飞猛进,大量产品被开发并应用到实际。在Google的引领下,互联网和各家通信公司纷纷把语音识别作为重要的研究方向。各家科技公司纷纷以语音助手为载体,争夺这个人工智能的入口:Google的Google Assistant、亚马逊的Alexa、微软的Cortana、苹果的Siri以及国内的一众语音助手产品,将语音识别技术带入了千家万户。

语音识别技术原理
语音识别技术从流程上讲有前端降噪、语音切割分帧、特征提取、状态匹配几个部分。而其框架可分成声学模型、语言模型和解码三个部分。
从流程上讲,我们的输入是声音波形,如下图:
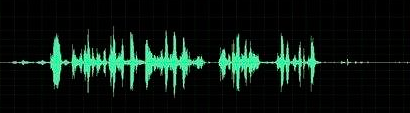
而在实际的场景中经常是带有噪声的,在较为复杂的场景中噪声甚至会比说话的声音还大,给语音识别造成很大的影响。所以一般在语音识别之前需要针对声音进行降噪,常见的降噪方法是称为波束形成的方法,该方法可以识别到声源的方位并对特定的方位进行增强。在语音识别之前,还需要把首尾端的静音切除,降低对后续步骤造成的干扰。这个静音切除的操作一般称为VAD。要对声音进行分析,需要对声音分帧,也就是把声音切开成一小段一小段,每小段称为一帧。分帧操作一般不是简单的切开,而是使用移动窗函数来实现,这里不详述。帧与帧之间一般是有交叠的,就像下图这样:
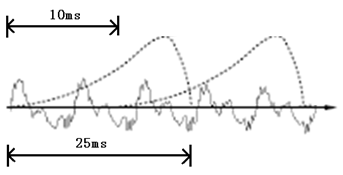
图中,每帧的长度为25毫秒,每两帧之间有25-10=15毫秒的交叠。我们称为以帧长25ms、帧移10ms分帧。
分帧后,语音就变成了很多小段。但波形在时域上几乎没有描述能力,因此必须将波形作变换。常见的一种变换方法是提取MFCC特征,根据人耳的生理特性,把每一帧波形变成一个多维向量,可以简单地理解为这个向量包含了这帧语音的内容信息。这个过程叫做声学特征提取。当然声学特征也不止有MFCC这一种。至此,声音就成了一个12行(假设声学特征是12维)、N列的一个矩阵,称之为观察序列,这里N为总帧数。观察序列如下图所示,图中,每一帧都用一个12维的向量表示,色块的颜色深浅表示向量值的大小。
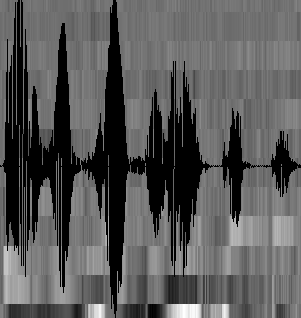
至此的话就剩下一个工作,就是如何将这个特征矩阵变成文本,需要经历下述三个步骤:
第一步,把帧识别成状态(难点);
第二步,把状态组合成音素;
第三步,把音素组合成单词。
如下图所示:
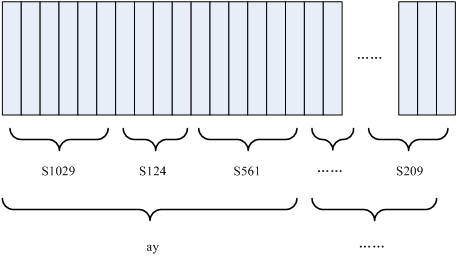
图中,每个小竖条代表一帧,若干帧语音对应一个状态,每三个状态组合成一个音素,若干个音素组合成一个单词。也就是说,只要知道每帧语音对应哪个状态了,语音识别的结果也就出来了。图中,每个小竖条代表一帧,若干帧语音对应一个状态,每三个状态组合成一个音素,若干个音素组合成一个单词。也就是说,只要知道每帧语音对应哪个状态了,语音识别的结果也就出来了。当然每帧语音对应的状态需要用到“声学模型”,声学模型是经过训练存储的帧和状态对应的概率。
语音识别的未来研究方向
现在语音识别的技术应用非常广泛,但是实现自然的人机交流还需要做很多工作:
(1)识别系统的强健性方面,有待进一步增强。现在,环境噪音和杂音对语音识别的效果影响最大。在嘈杂环境中必须有特殊的抗噪技术处理才能正常的使用语音识别,否则识别率很低,效果很差。目前针对中文的语音识别方面还存在着明显的不足,语言模型方面需要进一步完善。由于声学模型和语言模型在语音识别技术中起到基础性作用,所以必须在这方面有所突破,否则其它的都不可能实现。现在所使用的语言模型都是概率模型,文法模型没能得到运用,只有这一方面取得突破,计算机才能真正理解人类语言,这是一个难度非常大的工作。另外,随着硬件技术的不断发展,搜索算法、特征提取和自适应算法等这些核心算法将会得到不断改进。我们相信,半导体和软件技术的共同进步必将给语音识别技术打下坚实的基础。
(2)多语言混合识别方面和无限词汇识别方面需改善。现在使用的语音模型和声学模型有很多的局限性,如果突然从英语转为法语、俄语或者汉语,计算机就不会处理了,得到的东西完全不是我们想要的结果;如果人们偶尔使用了某些不太常见的专业术语,如”信息熵”等,计算机可能也会得到奇怪的结果。这不仅仅是因为模型具有局限性,同时也有硬件跟不上的原因。将来伴随这两方面技术的进步,声学模型和语音模型可能会理解各语言之间自然的切换。另外,因为声学模型的逐步改善,以及以语义学为基础的语言模型的改进,或许将能够帮助人们尽量少或完全不受词汇的影响,从而可实现无限词汇识别。
(3)在自适应方面需要更大的改进,达到不受口音、方言和特定人影响的要求。现实中的语音类型是各种各样的,从声音特征来说可以分为男音、女音和童音,另外,很多人的发音同标准发音有很大的差距,这就需要进行口音和方言的处理。即使同一个人,如果处在不同的环境中,或者在不一样的语境中,意思也可能不同。这些同样需要改进语音模型,让语音识别能适应大多数人的声音特征。
(4)语音识别系统在从实验室转化为商品的过程中,同样需要解决很多具体问题。比如,系统的识别速度、识别效率以及连续语音识别中剔除无意义语气词等问题。
总之,语音是人们工作生活中最自然的交流媒介,所以语音识别技术在人机交互中成为非常重要的方式。伴随计算机技术和语音识别技术的进步,语音识别系统的智能性和实用性将得到大幅提高。这将表明语音识别技术具有非常广泛的应用领域和非常广阔的市场前景。


{kind=link}
{kind=link}
{kind=link}