近日,特斯拉私有化的传闻甚嚣尘上,无论是证监会介入调查特斯拉涉嫌操纵股价,还是首席工程师的人事变动,都成为人们饭后的谈资。而自动驾驶技术也随着相关产业这最广为人知的公司的各种消息重新成为脍炙人口的话题。
要实现自动驾驶,手势识别是核心技术之一。不仅是特斯拉,谷歌、苹果以及福特等IT和汽车相关领域的公司都在研发汽车内部的手势控制功能。选择手势作为汽车人机交互的方式,主要是由于人们利用手势的形状和运动信息可以更加简便地传达语言无法完全表述清楚的感情和意义,它应用场合广、涵盖信息多。基于手势识别的人机交互在自然性和便捷性上都有着较大的优势,是它成为目前研究热点的主要原因。


同时,随着新型3D摄像头的出现, 3D手势识别在传统技术的基础上,借助深度摄像机,使图像从二维的RGB图像变为三维的具有深度信息的RGBD图像,提供了更加丰富的数据信息,使得一些关键问题的算法得以优化,增强了识别的准确度与效率。谷歌发布的专利中正是利用三维手势识别技术,实现了手势操纵的汽车控制台。
目前常规的手势识别系统分为建模和识别两大部分。建模部分即机器通过3D摄像机采集用户手部的点云,并将其与预先建立好的虚拟手部模型进行匹配,标注出模型的参数。识别部分是机器通过手势分割、特征提取、手势分类以及手部追踪等过程,识别用户手势的信息,并根据该信息进行对应的反馈。
手势建模
手势建模有两大类方法,判别式方法和生成式方法。
生成式方法在state-of-the-art的手势建模中相对更受欢迎,这种方法预先建立3D自由度的手部模型,并将其拟合到观察到的手部数据。这种方法中比较经典的方法是Oikonomidis 提出的通过26自由度的运动模型和多相机视图相匹配恢复3D手势,几何模型使用球体和截顶圆柱体等简单几何体渲染得到。他利用粒子群优化算法(PSO)最小化目标函数,将手部轮廓和边缘图作为观察线索计算,评估猜测姿势与多个观察视图之间的一致性。
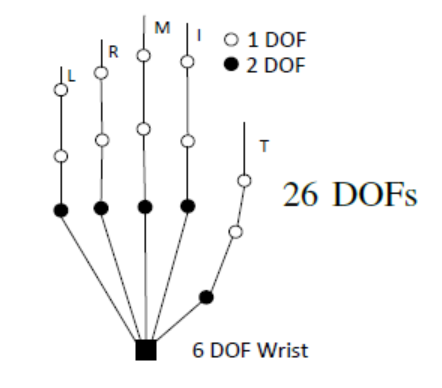
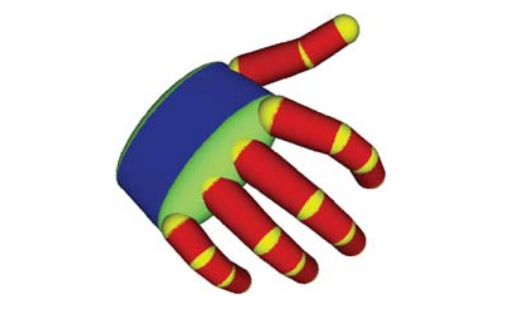
判别式方法则较为特殊,它不使用显式DoF约束3D手部模型,而是通过训练分类器,将特定外观的手部像素特征反向映射到未知的手部参数上。
手势识别
手势识别现阶段同样有两大流派,一类是传统的“特征表示+分类”,另一类是目前应用更广的神经网络
“特征表示+分类”的方法是先提取基于外观的特征描述子,再利用大家耳熟能详的支持向量机(SVM)、隐马尔可夫模型(HMM)等方法对手势进行分类,从而实现对观测手的姿势估计,具体内容就不再赘述了。
应用神经网络是现在较为流行的手势识别方式,这种技术具有自组织和自学习能力,具有分布性特点,能有效的抗噪声和处理不完整模式以及具有模式推广能力。Markus Oberweger在《Hands Deep in Deep Learning for Hand Pose Estimation》一文中设计了一个加入先验知识的CNN网络直接复原深度图中手的3D关节位置,并对每个关节点的预测用一个优化网络多次校准。Deep-prior的方法依靠深度网络学习到的“空间先验知识”而非IK来进行关节预测,使用Overlapping Regions来优化3D关节位置,提高精度;小的Region提供精确度,大的Region提供环境信息。
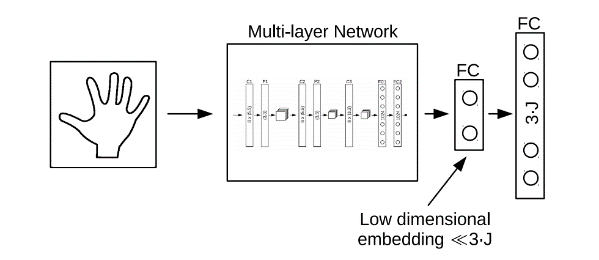
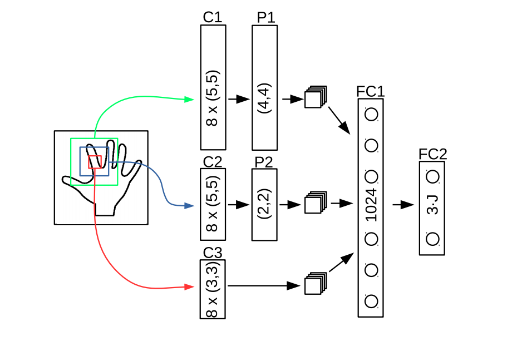
“工欲善其事,必先利其器”,“巧妇难为无米之炊“。手势识别的效果与准确度,与数据集的大小和多样性是密不可分的。手势数据集根据数据的来源分为两类,一类是真实数据,相机采集得到手部图像,再人工进行标注;另一类是合成数据,数据由计算机图像系统渲染生成,精确的标注在渲染时产生,避免了大量的人工标注工作的问题。
目前应用最广的数据集是由纽约大学提供的NYU Hand Pose,该数据集包含RGBD数据的超过72000张训练帧和8000张测试帧。NYU数据集是通过结构光传感器采集建立的,具有准确的标注,Ground truth包含36个关节点的标注,不同姿势表现出高度的可变性。训练集既包含单帧单用户的数据,也包含单帧多用户的样本。

合成数据比较知名的有libhand,它是一个开源许可的便携式库,用于渲染和识别人手的关节。用户可以自定义手部关节参数,来得到想要的虚拟图像数据。
现阶段,3D的手势识别技术因其数据信息更丰富的优点,已经受到越来越多研究人员的青睐,以3D作为研究重点的手势识别技术正逐渐与以2D为主的技术分庭抗礼。但在看到3D手势识别的进步和前景的同时,也不能盲目乐观,它仍然存在一些制约发展的难点,诸如:
1.判别方法在手势深度图低分辨率、手被其它物体遮挡或自我遮挡、手快速移动的情况中会产生大量错误。
2.庞大的数据标定工作
3.相似手势之间出现的误识别情况
4.手势在多视角下的识别问题
5.如何对于各种形态的手都能做到较好的识别
相信随着计算视觉技术的发展,这些难点都会一一解决,未来的3D手势识别技术交互将会愈加自然、应用将会愈加广泛。


{kind=link}
{kind=link}
{kind=link}