快速的定位声源对于人机交互很重要。现有的声源定位算法可分为波束形成、空间谱估计和到达时间差法三类,而从鲁棒性方面考虑,波束形成最佳。然而波束形成从原理上讲需要对空间进行全搜索,以找到使得麦克风阵列输出功率最大的位置,这导致了算法运行较慢。如何快速的搜索空间是这一问题的关键。可以从以下方面考虑:
麦克风采集的信号是离散的,这意味着只要空间划分够密,相邻格点到阵列的数字化时延间隔为零。那么,可以把这两个格点归为一类而不引起误差。这样空间可以分为均匀的类如下图所示:
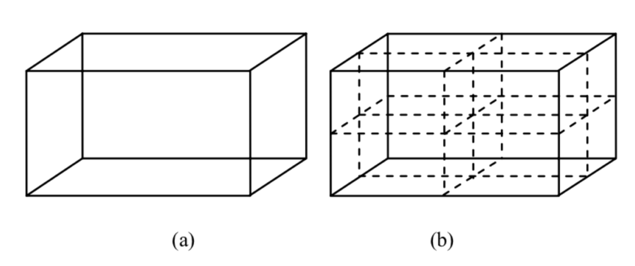
一个空间划分为均匀的八个区域,每个区域可以选择一点作为代表,这样可以减少搜素量。这样的划分可以按照需要一直进行下去。
进一步,根据声学研究的结果[1],格点即使偏离声源位置,只要由此导致的相位差在2/5内,其在麦克风阵列的输出功率仍然足够高,可以把它和声源位置划为一类。按照这样的标准,可以在前面均匀分割的基础上进一步的聚类,过程如下图所示:
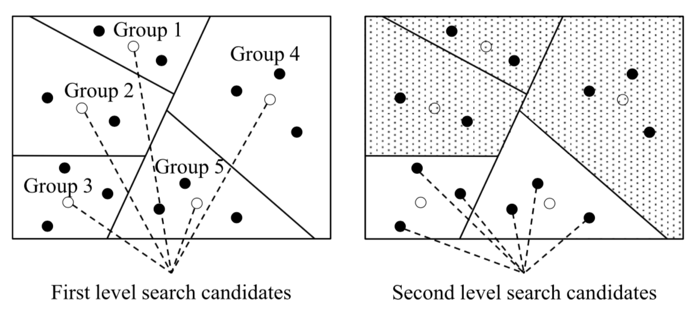
定位时首先计算各聚类的代表格点的阵列输出,找到最大的若干个聚类,然后再在这些类内进行详细的搜索,找到更为准确的声源位置[2]。
这种快速定位算法可以用在装有麦克风阵列的机器人上。
[1] D. Zotkin and R. Duraiswami, “Accelerated speech source localization via a hierarchical search of steered response power,” IEEE Trans. Speech Audio Process., vol. 12, no. 5, pp. 499–508, Sep. 2004.
[2] Dongsuk Yook, , Taewoo Lee, and Youngkyu Cho. “Fast Sound Source Localization Using Two-Level Search Space Clustering” IEEE TRANSACTIONS ON CYBERNETICS, VOL. 46, NO. 1, JANUARY 2016


{kind=link}
{kind=link}