视觉地点识别技术(Visual Place Recognition,简称VPR)主要是解决“我在哪儿?”这样一个问题。具体而言,VPR确定机器人或移动设备的当前视图是否来自过去曾经访问的地点或位置。通过视觉识别场所的能力,VPR可以作为解决计算机视觉和机器人领域许多问题的关键组件,如基于语义的图像检索,闭环检测和视觉定位。单点定位模块根据输入的同一地点的单张或多张图片,计算之后输出与地图库中相似度最高的若干个地点的坐标与概率。
视觉地点识别技术可以被认为是一种图像检索技术,即对目前所观测到的图像与之前到过地点观测到的图像进行匹配,并由此进行地点的识别和定位。视觉地点识别所面临的两大挑战分别是环境变化和视角变化问题。环境变化问题是指同一地点随光照、昼夜和季节等呈现出识别的问题,而视角变化是指统一地点在不同视角观测下呈现出识别的问题。
为了解决视觉变换和环境变化的问题,在本项目中尝试使用神经网络作为特征描述子,同时通过物体检测算法构建局部标志物拓扑关系检测,将两者的输出进行融合比对,从而增加算法识别的鲁棒性。训练得到的网络用作提取视觉特征的描述器,因此首先需要训练出准确率较高的网络模型,然后再将此模型应用到定位导航的系统当中。其中,网络模型训练架构如图所示。
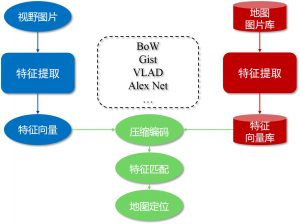
最终,训练得到的网络可以用于构建定位系统,整体架构分为离线和在线两部分,离线与在线模式的算法架构一致。离线模式下,通过网络前向传播与编码压缩的过程,将地图库中的图片提取为特征向量语义库;在线模式下,将输入的查询图片提取为特征向量,并与地图库中的数据进行匹配,筛选出最为接近的若干个输出。



{kind=link}
{kind=link}
{kind=link}
{kind=link}