前言:
基于联结时序分类(CTC)的声学模型不再需要对训练的音频序列和文本序列进行强制对齐,实际上已经初步具备了端到端的声学模型建模能力。但是CTC模型进行声学建模存在着两个严重的瓶颈,一是缺乏语言模型建模能力,不能整合语言模型进行联合优化,二是不能建模模型输出之间的依赖关系。RNN-Transducer针对CTC的不足,进行了改进,使得模型具有了端到端联合优化、具有语言建模能力、便于实现Online语音识别等突出的优点, 更加适合语音任务。
RNN-T介绍:
RNN-Transducer模型实际上是在CTC模型的一种改进。因此,本文从CTC模型出发,一步步引入为什么要使用RNN-T对语音识别任务建模,RNN-T模型还有什么问题存在。
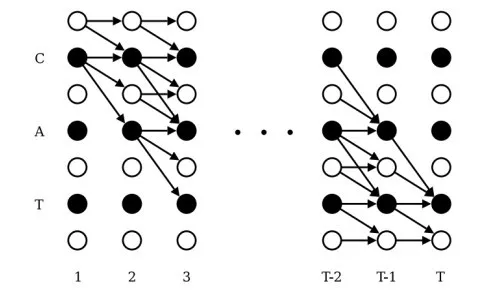
在联结时序分类模型(CTC)提出之前,深度神经网络-隐马尔可夫模型占据着语音识别的江山。但是其需要预先对数据进行强制对齐,以提供给模型逐帧标记,用于监督训练。CTC巧妙对给定输入序列,所有可能输出路径的条件概率进行建模,实现了不需要强制对齐就能进行序列与序列之间的转换。由于CTC要对所有可能的路径求概率值,如果枚举所有路径的话会有很高的计算代价,因此将动态规划的思路引入CTC路径的概率计算过程,这就是前后向算法。
RNN-T优缺点:
CTC对于语音识别的声学建模带来了极大的好处
1)化繁为简,不在需要强制对齐,可以使用文本序列本身来进行学习训练
2)加速解码,大量Blank的存在,使得模型在解码过程中可以使用跳帧操作,因此大大加速了解码过程。
但是CTC模型仍然存在着很多的问题,其中最显著的就是CTC假设模型的输出之间是条件独立的。这个基本假设与语音识别任务之前存在着一定程度的背离。此外,CTC模型并不具有语言建模能力,同时也并没有真正的实现端到端的联合优化。
针对CTC的不足,Alex Graves在2012年左右提出了RNN-T模型,RNN-T模型巧妙的将语言模型声学模型整合在一起,同时进行联合优化,是一种理论上相对完美的模型结构。RNN-T模型引入了TranscriptionNet也就是图中的Encoder(可以使用任何声学模型的结构),相当于声学模型部分,图中的PredictionNet实际上相当于语言模型(可以使用单向的循环神经网络来构建)。模型中比较新奇,同时也是最重要的结构就是联合网络Joint Net,一般可以使用前向网络来进行建模。联合网络的作用就是将语言模型和声学模型的状态通过某种思路结合在一起,可以是拼接操作,也可以是直接相加等,考虑到语言模型和声学模型可能有不同的权重问题,似乎拼接操作更加合理一些。

像CTC一样,模型需要生成一张解码图,在解码图上使用前后向算法对所有可能的路径进行概率计算,其解码图如下所示。
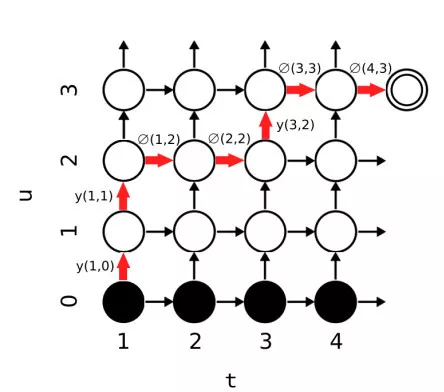
解码图中所有横向转移表示根据第t个声学模型状态和第u个预测出的标记,解码出空转移的概率,垂直方向的转移均为非空转移。
RNN-T模型本身是比较完善的,几乎汇集了所有模型的优点
(1)端到端联合优化
(2)具有语言模型建模能力
(3)具有单调性,能够进行实时在线解码。
如果非得挑RNN-T模型的不足的话无非两点:
(1)模型比较难以训练
(2)模型的一些路径不合理,并不完全适用于语音任务。
针对第一点问题,比较好的解决思路就是进行预训练,其中Google尝试了一种CTC多级预训练机制,模型对声学模型和语言模型分别进行预训练,其中声学模型预训练模型使用CTC作为损失函数,在越底层使用的建模单元越小,在越高层,使用的建模单元越大,然后使用预训练模型与RNN-T声学模型部分同级的权重去做预训练,虽然这个一个繁琐的工作,但是也不失为一种很好的预训练方法。
针对第二个问题,我们可以看RNN-T中的标红路径,虽然这是一条RNN-T的可行路径,但是实际上并不是很合理,因为其针对第一个声学模型状态解码出来了两个非空输出标签,一个比较形象的例子就是在识别字符串‘hello’的过程中,根据第一个声学模型的发音单元就解码出了‘h’和‘e’两个输出标记。因此一种对模型增加一种合理的约束,使得模型没解码一个语言模型的状态均需要消耗掉一个声学模型状态,也就是时间步加一,则可以将解码图转换成如下形式。

改进后的模型我们称之为Recurrent Neural Aligner(RNA),模型显著的减小了解码空间,并且加快了计算的效率。


{kind=link}
{kind=link}
{kind=link}
{kind=link}