一、前言
类脑芯片,又称神经形态芯片或神经芯片,是当前新型的一种计算硬件,其设计受到生物神经系统的启发,与传统的计算硬件CPU、GPU等不同,类脑芯片旨在模仿大脑中神经元和突触之间的相互作用,以实现高度并行、事件驱动和能耗极低的计算。目前的类脑芯片以多核架构作为主流,包含多计算核心和片上网络(Network-on-chip,后统称NoC)两大部分。计算核心作为基本计算单元,通过NoC进行互联。NoC作为类脑芯片中数据转发的基石,其设计被广泛探讨。NoC主要由拓扑结构、路由算法和仲裁策略三大部分组成,根据不同数据流量需求对拓扑结构与路由算法进行恰当的设计,可以有效地提升整体性能。类脑芯片模拟了生物神经元的机制,采用脉冲编码数据,该类数据具有稀疏、离散等特点,基于地址事件驱动(Address-Event Representation, AER)协议,实时响应外部输入刺激。这样异步且稀疏的脉冲数据,对于NoC的设计提出了更高效率的要求,本文主要介绍NoC中的路由算法,着重介绍利于脉冲数据的高性能多播算法以及部分最新研究成果,进行相关算法的分类对比,并预测未来发展趋势。
二、类脑数据及其传输特性
脉冲神经网络(Spiking Neural Network,后统称SNN)作为受生物大脑启发的第三代神经网络,通过模拟神经元动力学和突触连接等特性,具有丰富的时空特征。区别于第二代神经网络使用高精度浮点型数据进行计算,SNN基于稀疏脉冲进行计算,对于数据容量的要求大大降低,便于低功耗处理器的实现,目前已成为应用于类脑芯片的基础模型,完成相应的任务。图1展示了常见的三层SNN网络。
图1 三层SNN示例图[1]
SNN中的脉冲数据具有显著的稀疏性和异步时序性,对于实际任务的诸如图像视频等训练数据进行频率或时间编码,进行尽可能准确的信息表达。数据的稀疏异步特性需要数据转发过程低时延的支持。同样的,在SNN学习推理过程中,常出现相同数据从一个神经元转发到不同神经元中的情况,这种情况在层与层间尤为明显,例如常见的全连接层、BP反向传播时梯度的计算等过程,由于硬件本身容量的限制和网络映射优化的结果,不同的神经元被放置在不同的计算核心中,这些计算核心通过NoC进行互联,分布于不同物理区域。对于这种情况,批量地转发相应数据的路由算法需要进行考量。
针对如上所述的类脑数据及其传输特性,适配的NoC数据转发模式及其对应的路由算法相应地产生。本文介绍NoC中的常规数据转发模式–数据单播(Unicast)和适配类脑数据的优化转发模式—数据多播(Multicast)。前者在同一时刻仅转发具有单一目的地的单个数据包,对于具有多个目的地的数据包,需要路由器串行地转发数据包到不同计算核,导致转发该数据包的整体时延较大,不利于NoC的通信效率以及SNN的高效学习推理。后者为更为高效的转发模式,也是本文介绍的重点。追溯到早期的互联网无线通信,相关的传输协议提供了多播和广播的思路,即同时转发多目的地数据包以节省时间[2],借用其中的概念,适用于NoC的数据多播转发机制得到发展,利用多播转发可以降低带宽链路需求,提高传输可靠性。面对类脑的脉冲数据,多播机制凭借其便捷高效的转发,同时结合异步策略批量转发脉冲到多核心,满足稀疏脉冲下的实时计算,适配类脑数据的传输计算特性。
三、路由多播算法介绍
本节主要介绍NoC中路由多播算法的基本概念,从整体上说明多播算法相较于传统单播算法的优势以及存在的一些问题,介绍多播中常见的死锁问题及对应解决措施,根据目前多播算法的具体分类详细介绍部分经典算法,最后介绍近年针对不规则拓扑的高效自适应多播算法,总结其优势。
3.1 路由多播定义
数据多播又叫数据组播,即同时对具有多个目的地的数据包进行转发,到达各自的目的地。本文使用例子说明单多播的具体区别,并简要介绍多播的优势。这里主要针对数据包收发时延和链路资源两个方面进行说明,采用基于拓扑的多播模式为例。

图2 4×4 mesh网络多播示例
对于图2所示的4×4 mesh网络,待转发数据包同时具有D1、D2、D3三个目的路由,假设不存在其他数据包的干扰,单个数据包的路由算法都采用最短路径,同时路由器内部的仲裁等操作在一个时钟周期都能够完成,使得理想化的时延仅取决于转发路径长度。时延方面,多播模式相较于单播模式具有更低的转发延迟。单播模式下数据包遵循串行转发,即每个时间步新数据包从源节点被转发,以Tx代表时间步长,按D1、D2、D3顺序转发对应的数据包,整体时延达到4个时钟周期;在多播模式下,数据包承载多个目的地同时进行转发,最大时延仅取决于最长数据路径,因此整体时延为3个时钟周期。带宽资源方面,多播一定程度减少链路带宽资源的消耗,避免单播中同一路径的多次使用导致的额外开销。如图2中,10-11号路由间的链路在单播中会被使用两次,而多播只会使用一次。多播通过提供更低的时延和带宽消耗,来提高整个NoC的数据通信性能。
与此同时,多播通信仍存在一些挑战。首先是需要更加复杂的路由算法来进行支持;其次,在同一路由的多个端口同时进行转发会导致路由间通道情况更加复杂;最重要的一点是多播相较于单播更容易发生数据死锁,这在数据通信中是十分致命的问题。
3.2 路由死锁定义与解决措施
死锁是数据通信领域内的一大重点,是指多个数据包或消息任务在网络中争夺资源导致的路由间的永久阻塞,从而导致数据或消息任务在没有外界干扰的情况下永远无法转发到目的地。在大量的研究的基础下,Coffman等人总结了死锁产生的四个条件[3]:
• 互斥:数据或任务声称对其所需的资源拥有独占控制权;
• 保持等待:数据或任务在等待其他资源时保留已分配给它们的资源;
• 没有抢占:在资源被使用到完成之前,不能强行从持有资源的数据或任务中移除该资源;
• 循环等待:存在数据或任务的循环链。
以上四个条件必须同时得到满足才可以发生死锁,如图3所示,P1、P2、P3和P4四个数据包依次占用了一条路径资源,并请求额外的资源,但请求的资源又被相邻的数据包占据,以P1和P2数据包为例,P1 数据包从路由器A发往B并最终期望达到路由器C,P2 数据包从路由器B发往C并最终期望达到路由器D。P1、P2分别占用AB、BC链路,P1请求的BC链路目前没有得到释放,原因在于P2请求的CD链路没有得到释放,导致P1、P2数据包无法进行后续转发。因循环的数据路径以及相互的资源占用从而导致四个数据包产生死锁。

图3 死锁现象的一种示例
死锁的产生会严重地影响整个NoC的通信性能,因此在路由算法的实现过程中,必须将死锁的产生和解决纳入考量。解决死锁的办法主要有三种,分别对应上文中提到的死锁条件。
- 提供更多资源:该方法对应解决死锁条件中的互斥,主要采用两种策略:增加虚拟通道和消费通道。前者通过在路由端口增加额外缓存,避免单一通道资源占用导致的死锁,但是并不增加额外的物理传输通道[4];后者与前者相反,通过增加物理传输通道,从而在转发过程中提供更多资源[5]。
- 避免数据环路:该方法对应解决死锁条件中的数据环路,主要通过设计合理的路由算法,来避免环路的发生。数据环路产生的根本原因在于数据的八种转向都可以执行,常见的无死锁路由算法在数据单播中包括XY路由算法[6]奇偶转弯算法[7]等,通过限制数据流量中的某些转向,从而确保数据转发路径中不会出现环路,从而避免死锁。
- 取消任务对资源的占用:该方法对应解决死锁条件中的资源占用,即取消阻塞数据包对通道的占用请求[8]。一般考虑一个确定的等待时间,如果数据包在路由缓存中长期未转发,则网络考虑出现死锁,取消其占用请求,并利用额外的死锁缓存通道来进行缓存,使得路由资源重新得到释放[9] [10]。
以上三种方法各有优劣,或是借用额外的资源开销、或是修改路由规则降低转发效率,都可以有效地阻止死锁的产生。
3.3 数据多播算法分类
数据多播算法主要分为两大类:基于路径的数据多播和基于拓扑的数据多播[11]。
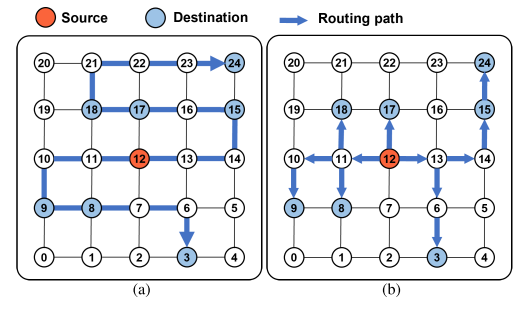
图4数据多播分类示例,左为基于路径,右为基于拓扑[10]
基于路径的数据多播算法主要依靠路由网络中的哈密顿路径进行转发,因此需要依赖规则拓扑进行静态的路径规划,具有较强的拓扑依赖性。如图4所示,算法对规则拓扑下的路由进行排序标号,以此构成一条哈密顿路径,数据包按照目的地升序降序依次转发到对应的目的路由。基于路径的数据多播优缺点都比较明显:优点在于数据包阻塞的概率很低,因为每条消息最多请求哈密顿路径的上下两个信道,同样可以降低死锁发生的概率;不足在于多播路径中源节点和其中一个目的节点之间的子路径通常不是最短路径,在较低通信量的情况下数据包的延迟会相应增加。
基于拓扑的数据多播算法主要依靠路由器对于数据包分支复制、同步转发的支持,无需依赖拓扑的规则程度,依据相应的路由算法如XY路由等进行转发,在中间路由节点进行分支转发,因此数据路径的生成也是动态的,并且不需要遵循任何次序。基于拓扑的路由算法不需要对目标进行排序,并且根据选择的单播路由算法,总是选择源节点与所有目标节点之间的最短路径。然而在通信量较大的情况下中间节点容易出现阻塞,导致整体性能较差,遭受较高的多播消息延迟。
表1展示了不同类型的多播算法,其中包括了对拓扑依赖情况和死锁解决方法的分类。基于路径的多播大部分依靠规则拓扑,以MP[12]算法为开始,逐步衍生发展出CP[13]、HAMUM[14]、HOE[15]等算法,通过提供更多资源和避免数据环路的方法来杜绝死锁情况的发生。基于拓扑的多播大部分不依靠规则拓扑,以CTR[16]算法开始,逐步完善发展出HTA[17]、SmartFork[18]、MRBS[10]等算法,这些算法主要通过引入额外的死锁检测机制和死锁恢复缓存来解决死锁问题,针对不同延迟问题采取同步或异步的数据包复制策略来完成转发;基于拓扑的多播中还有一类算法考虑数据链路的复用情况,采取了类似路径的策略,依靠规则拓扑来优化链路资源并保证最小路径,以RPM[19]和IMM[20]算法为主。
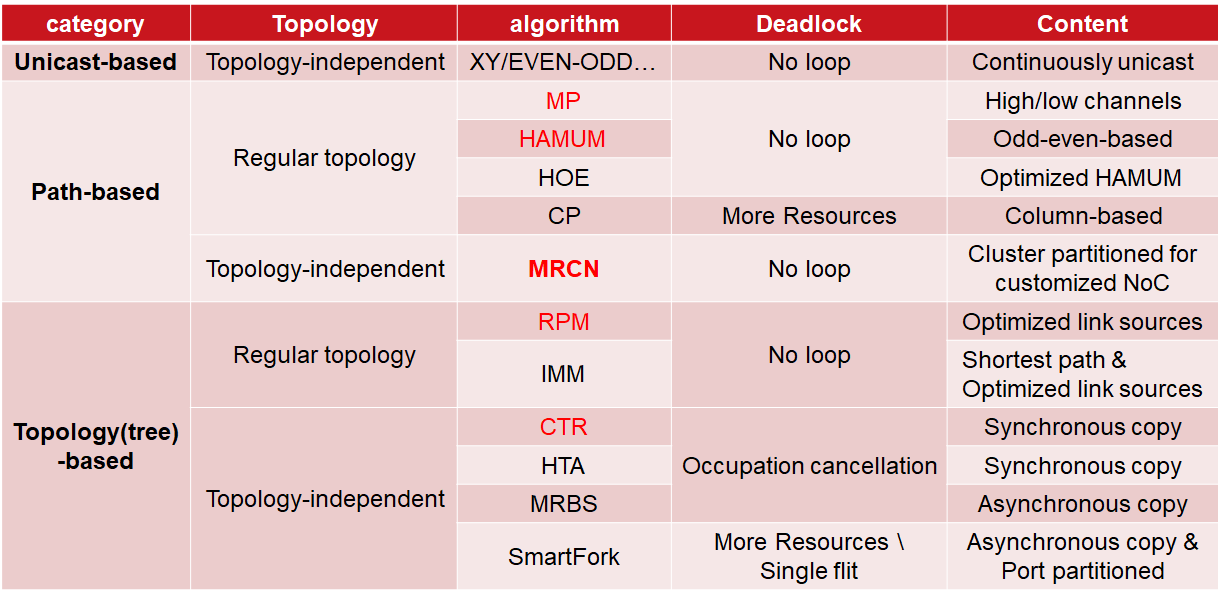 表1数据多播算法汇总
表1数据多播算法汇总
下文为分类中的典型方案进行介绍,包括MP、CTR和RPM算法。
-
-
- 基于路径的算法—MP(multipath routing)
-
该方法提出了高通子网络和低通子网络的概念,将实际的物理网络划分为若干子网络。基于路径的多播首先需要对拓扑中的路由节点进行标号,再确定存在哈密顿路径。图5中展示两种划分,高通子网络只允许小标签到大标签的路径,低通子网络只允许大标签到小标签的路径,本质是对不同目的地数据包做分区,将目的地标号大于源节点的划入高通,小于的划入低通。
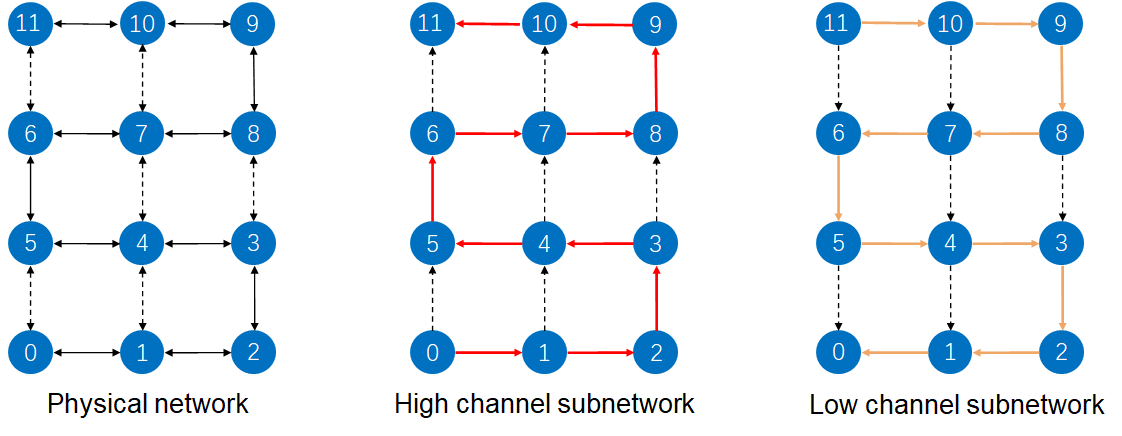
图5左:物理网络、中:高通子网络、右:低通子网络
整个MP算法不仅仅将网络分为高低两个子网络,而是根据路由器的东西南北四个方向,将网络分为四个子网络,包含两个高通网络DH1、DH2和两个低通网络DL1、DL2,提高整体的效率降低时延,并且四个子网络互不影响。在四个子网络中分别遵循XY路由,同时满足标签大小的要求。

图6 MP算法示例:粉色路由为源节点,褐色路由为目的节点
MP算法通过划分高低子通道的方式来避免路径环路,从而达到无死锁的情况,但是路径并非最短路径。
-
-
- 基于拓扑的算法—CTR(conventional tree-based router for multicast)
-
CTR算法中将目的地信息全部保存在数据中,每到一个路由就计算其中所有可能的输出方向,如果存在不同输出方向,则进行数据包复制,并修改其中的目的地信息,不断地完成数据包的全部转发过程。该算法采用同步复制的策略,数据的转发必须得到所有输出端口的支持,一旦有某一个端口被占用,数据包不会进行分支复制和转发,会等待到所有输出端口都空闲,才进行数据的复制转发。因为这样的原因,常会出现无法避免的死锁。

图7 CTR算法示例以及数据包格式
针对可能出现的死锁情况,作者通过剪枝机制控制多播分支来解决死锁和争用。当流控制停止先前节点中的微片时,也在这些节点处执行修剪。然后,修剪后的分支可以自由前进和释放可能阻塞其他消息的通道。此时本质上将数据复制的策略动态调整为了异步复制的策略。假设单播消息的路由功能是无死锁的,所描述的路由机制能够从使用基于拓扑的多播所产生的死锁中恢复。
-
-
- 基于拓扑的算法—RPM(Recursive Partitioning Multicast)
-
RPM算法在CTR算法的基础上进行思考,如图8所示,a图表示CTR算法的过程,b图则代表其他可能。在两种情况下,尽管数据包复制次数相同,但物理链路的资源消耗存在差别。a图中11条链路被使用,而b图中仅5条,降低了带宽需求。带宽使用量的增加可能会导致链路和路由器端口发生争用,从而增加延迟。此外,与b相比,a由于更多的操作(缓冲区读/写、交叉遍历和链接遍历)而消耗更多的功率。因此,为了尽可能寻找最优的链路开销,RPM算法得以产生。

图8 两种基于拓扑多播的示例
该算法的基本思想是基于网络中的所有目的地位置来计算路由路径,并根据当前路由器的位置递归地划分网络。当前节点使用新分区及其数据包的目的地列表来计算输出端口,并执行转发。将路由网络依据源节点划分为最多8个分区,并遵循一定的转发规律,来完成最优化路径的生成并进行相应的数据转发。由于引入分区,隐性地禁止了部分转向,数据死锁得以避免。
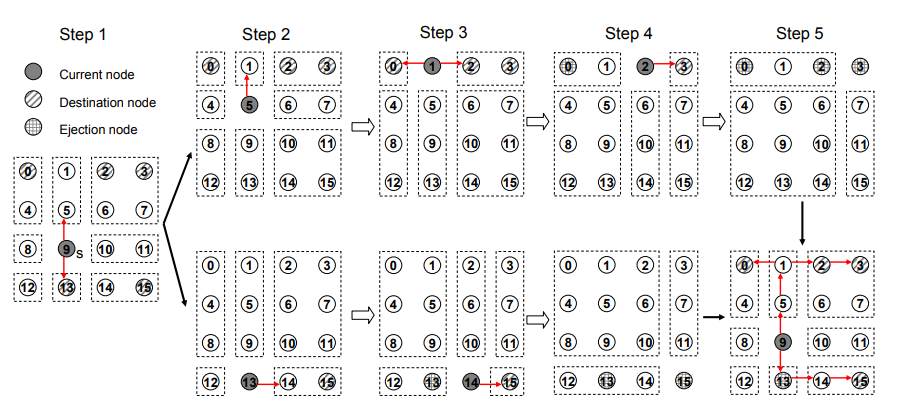
图9 RPM算法示例
3.4 无规则拓扑的适应多播路由
前面介绍了基础的多播算法,类脑芯片近期的发展对于NoC网络提出了更多的需求,非规则拓扑的应用增多,常规的多播方法难以进行应用。在基于不规则拓扑的NoC中实现吞吐量优化的多播路由是具有挑战性的,因为死锁条件变得复杂,并且应用标记规则所需的哈密尔顿路径可能不存在。这里介绍MRCN(multicast routing for customized NoC)这项工作,该研究提出了一种用于定制NoC(MRCN)的无死锁和吞吐量增强的多播路由, 通过利用拓展路由和特殊的路由器标记规则来构造适合的数据路径并确保路由无死锁,此外,目的地路由器分区和流量感知自适应分支被结合在一起,以减少分组路由跳数[21]。
MRCN方法整体流程分为以下三个部分:哈密顿路径的搜索算法、目的地路由划分算和自适应分区路由算法。其中前两部分是静态配置、后一部分是实时进行。
哈密顿路径的搜索算法又称为标记路径搜索LPS,旨在找到一条包含尽可能多的路由器路径,以最小化未标记路由器的数目,也就是最大化标记路由器的数目。作者在大量实验中证明,当优先标记度最低的路由器时,子拓扑中剩余未标记路由器的链路复杂度最大化。因此,LPS试图通过标记具有最低程度偏好的路由器来最大化标记路由器的数量。以图10为例,通过依次选择临近的具有最小度的路由来完成路径构建,若出现相同度的情况,则根据下一级跳数距离的路由器的度数来进行判断。对于图10中起始路由器的选择,R1、R15、Ru1都具有1的最低度数,那么计算距离这些路由器1跳的路由器度数,对应则是R2、R14以及R11,度数分别为3、3、4,因此Ru1不作为考虑。后续针对R1和R15计算距离2跳的路由器度数,对应则是R3、R7、R8和R11、R12、R13,度数分别为13和14,因此R1整体具有更低的跳数,有着更复杂的链路可能,因此选择R1作为起始路由,后续依据此规则继续加入路由器,构成路径。
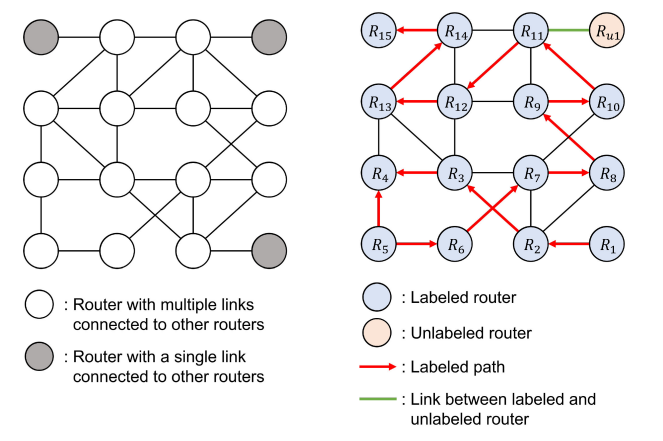
图10 LPS生成最优路径示例
虽然LPS确保了死锁自由,但它也必须尽可能优化降低转发时延。因此,引入目的路由器分区和自适应分支。
目的地路由器分区(DRP)旨在消除访问定制NoC中所有路由器的最坏情况路径,从而提高整体吞吐量。为了减少确定最长标记路径的最大集群的大小,DRP尝试平衡集群大小,集群的数量等于与给定源路由器相邻的路由器的数量。每个集群中与给定源路由器相邻的路由器被唯一分配为入口路由器。每个集群轮流附加一个非附属路由器,以减少集群之间路由器数量的差异,并且每个集群中新添加的路由器必须符合标签顺序。
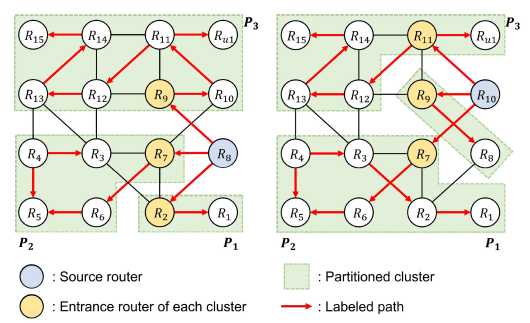
图11 DRP分区示例
自适应分支(ADB)利用每个分区集群内的路径多样性来分散网络流量。作者定义了标签绕行条件(LDCs),以防止循环等待和保持等待,从而仅在这些情况下允许替代路径路由。
标签绕行条件1(LDC1):数据包的目的地是绕行方向上的下游路由器;且绕行方向的下游路由器中的输入缓冲区为空。
标签绕行条件2(LDC2):在绕行方向上,有一个目的地的标签高于或低于当前路由器和下游路由器;且整个数据包可以存储在绕行方向上下游路由器上的可用输入缓冲空间中。
LDC1旨在使具有目的地的分组能够被路由到下游路由器,因为分支数据包直接从目的路由弹出而不需要额外缓存。当有足够的输入缓冲区空间在下游路由器中容纳整个数据包时,LDC2被创建为支持分支。通过建立自适应分支,可以有效利用链路资源并减少转发时延。
实验验证,无论是对于规则或是非规则拓扑,在高流量多播情况下,MRCN相较于先前的工作都有较大提升,特别是反映在包的平均时延和整个路由网络的吞吐量上,如图12的实验结果所示。
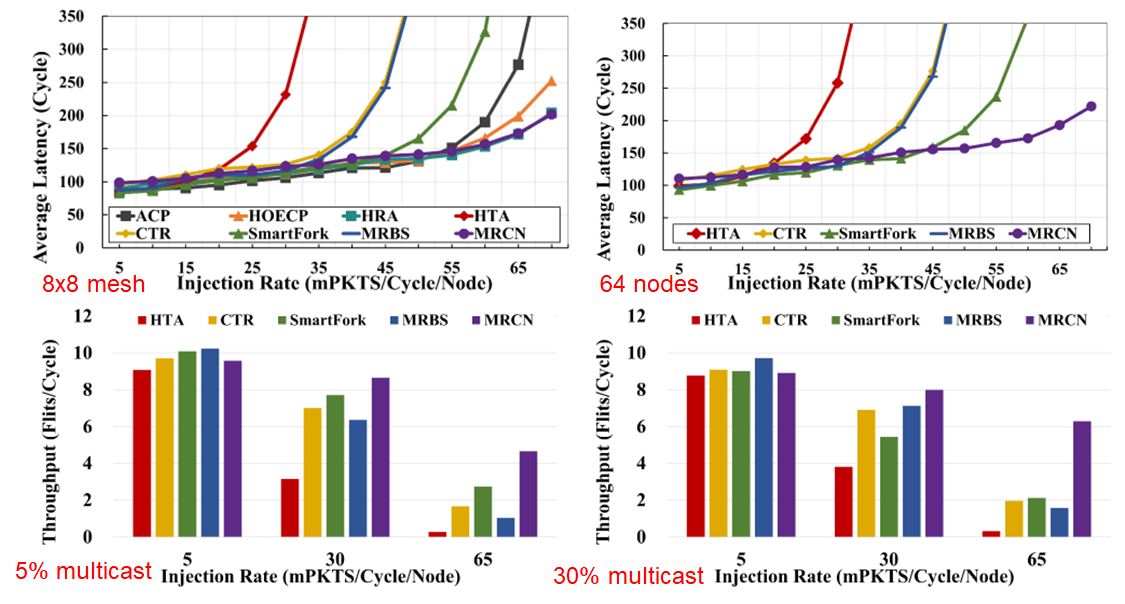
图12 MRCN和其他方法的实验结果
四、总结
本文主要介绍类脑芯片中的数据形式及其特性,针对类脑数据的传输需求,详细介绍了其中片上网络NoC的数据转发模式和路由算法,其中主要介绍了数据多播算法和死锁问题,包括两种类型的多种路由算法以及相应的死锁解决办法。
在未来,可能会有更多的特定的拓扑结构被应用到类脑芯片上,可能是不规则的适配特定硬件的拓扑,也可能是类脑的大规模架构。同时类脑数据集本身的发展、数据的转发随着神经网络的优化发展同样会产生新的需求。在这些情况下,现有的多播算法可能无法很好地适应[22]。数据方面,在后续面对更大规模类脑数据、更具有生物解释性的脉冲编码的情况下,需要结合数据进行特别的NoC数据压缩算法,根据压缩情况开展路由优化研究;网络方面,需要在后续面对大规模网络、不规则拓扑的情况下,需要考虑到一些特殊的启发式分区算法,以及相应的映射和路径规划算法,可以采取路由表等形式或是抽象建模来求解最优化问题进行路由转发,使得整体的NoC架构和数据转发更加智能,贴近生物神经元脉冲刺激的工作模式,逐步接近真正的类脑智能。
参考文献
[1] Chen G K, Kumar R, Sumbul H E, et al. A 4096-neuron 1M-synapse 3.8-pJ/SOP spiking neural network with on-chip STDP learning and sparse weights in 10-nm FinFET CMOS[J]. IEEE Journal of Solid-State Circuits, 2018, 54(4): 992-1002.
[2] Lee S J, Su W, Hsu J, et al. A performance comparison study of ad hoc wireless multicast protocols[C]//Proceedings IEEE INFOCOM 2000. Conference on Computer Communications. Nineteenth Annual Joint Conference of the IEEE Computer and Communications Societies (Cat. No. 00CH37064). IEEE, 2000, 2: 565-574.
[3] Coffman E G, Elphick M, Shoshani A. System deadlocks[J]. ACM Computing Surveys (CSUR), 1971, 3(2): 67-78.
[4] Boppana R V, Chalasani S, Raghavendra C S. On multicast wormhole routing in multicomputer networks[C]//Proceedings of 1994 6th IEEE Symposium on Parallel and Distributed Processing. IEEE, 1994: 722-729.
[5] Dally W J. Virtual-channel flow control[J]. IEEE Transactions on Parallel and Distributed systems, 1992, 3(2): 194-205.
[6] Zhang W, Hou L, Wang J, et al. Comparison research between xy and odd-even routing algorithm of a 2-dimension 3×3 mesh topology network-on-chip[C]//2009 WRI Global Congress on Intelligent Systems. IEEE, 2009, 3: 329-333.
[7] Chiu G M. The odd-even turn model for adaptive routing[J]. IEEE Transactions on parallel and distributed systems, 2000, 11(7): 729-738.
[8] Malumbres M P, Duato J, Torrellas J. An efficient implementation of tree-based multicast routing for distributed shared-memory multiprocessors[C]//Proceedings of SPDP’96: 8th IEEE Symposium on Parallel and Distributed Processing. IEEE, 1996: 186-189.
[9] Kumar D R, Najjar W A, Srimani P K. A new adaptive hardware tree-based multicast routing in k-ary n-cubes[J]. IEEE Transactions on Computers, 2001, 50(7): 647-659.
[10] Yang M C, Lee Y S, Han T H. MRBS: An area-efficient multicast router for network-on-chip using buffer sharing[J]. IEEE Access, 2021, 9: 168783-168793.
[11] Velayudham S, Rajagopal S, Kathirvel S, et al. An overview of multicast routing algorithms in network on chip[C]//Intelligent Computing Paradigm and Cutting-edge Technologies: Proceedings of the Second International Conference on Innovative Computing and Cutting-edge Technologies (ICICCT 2020). Springer International Publishing, 2021: 163-178.
[12] Lin X, McKinley P K, Ni L M. Deadlock-free multicast wormhole routing in 2-D mesh multicomputers[J]. IEEE transactions on Parallel and Distributed Systems, 1994, 5(8): 793-804.
[13] Boppana R V, Chalasani S, Raghavendra C S. Resource deadlocks and performance of wormhole multicast routing algorithms[J]. IEEE Transactions on Parallel and Distributed Systems, 1998, 9(6): 535-549.
[14] Ebrahimi M, Daneshtalab M, Liljeberg P, et al. HAMUM-A novel routing protocol for unicast and multicast traffic in MPSoCs[C]//2010 18th Euromicro Conference on Parallel, Distributed and Network-based Processing. IEEE, 2010: 525-532.
[15] Bahrebar P, Stroobandt D. Improving hamiltonian-based routing methods for on-chip networks: a turn model approach[C]//2014 Design, Automation & Test in Europe Conference & Exhibition (DATE). IEEE, 2014: 1-4.
[16] Malumbres M P, Duato J, Torrellas J. An efficient implementation of tree-based multicast routing for distributed shared-memory multiprocessors[C]//Proceedings of SPDP’96: 8th IEEE Symposium on Parallel and Distributed Processing. IEEE, 1996: 186-189.
[17] Kumar D R, Najjar W A, Srimani P K. A new adaptive hardware tree-based multicast routing in k-ary n-cubes[J]. IEEE Transactions on Computers, 2001, 50(7): 647-659.
[18] Konstantinou D, Nicopoulos C, Lee J, et al. Multicast-enabled network-on-chip routers leveraging partitioned allocation and switching[J]. Integration, 2021, 77: 104-112.
[19] Wang L, Jin Y, Kim H, et al. Recursive partitioning multicast: A bandwidth-efficient routing for networks-on-chip[C]//2009 3rd ACM/IEEE International Symposium on Networks-on-Chip. IEEE, 2009: 64-73.
[20] Zhong M, Wang Z, Gu H, et al. An improved minimal multicast routing algorithm for mesh-based networks-on-chip[C]//2014 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC). IEEE, 2014: 775-779.
[21] Lee Y S, Kim Y W, Han T H. Mrcn: Throughput-oriented multicast routing for customized network-on-chips[J]. IEEE Transactions on Parallel and Distributed Systems, 2022, 34(1): 163-179.
[22] Ge M, Ni X, Qi X, et al. Synthesizing Brain-network-inspired Interconnections for Large-scale Network-on-chips[J]. ACM Transactions on Design Automation of Electronic Systems (TODAES), 2021, 27(1): 1-30.

{kind=link}
{kind=link}
{kind=link}
{kind=link}