一、前言
为了更好地了解大脑智力来源并探索新的生物启发式计算,一种被称为脉冲神经网络(Spiking Neural Network, SNN)的新型神经网络技术逐渐兴起,并已被成功应用于包括视觉识别和分类在内的多种任务。此外,神经形态硬件使得大规模网络实时运行成为了可能,这也是神经机器人控制、脑机接口和机器人决策等诸多应用的关键要求。为了满足此类系统的要求,高能效、高智能脉冲神经网络硬件架构的实现是核心挑战之一。近年来,一种基于分布式计算核心与高能效片上网络的主流类脑计算架构正在被广泛研究。本文主要介绍了上述类脑计算架构的技术发展现状,分析并比较各种实现技术特性并预测了未来发展趋势。
二、大脑与神经形态硬件
人类大脑的智力水平一直是AI智能硬件设计的追求目标。近年来,人工智能技术飞速发展,基于联结主义的多层人工神经网络 (Artificial Neural Network, ANN) 在第一代感知机的基础上加入了非线性单元和隐藏层,使得其学习非线性特征成为了可能,人工神经网络逐渐成为人工智能领域的研究重点([1],[2],[3]),例如著名的DNN、CNN和RNN等,它们在图像识别[4,5]、目标感知[6,7]、自然语言处理[8,9]等应用上展现出了优秀的性能,尤其是著名的用于围棋竞技的AlphaGo[10,11,12]与用于蛋白质预测的AlphaFold [13],已经具有超越人类的能力。然而,ANN取得的成就基本上都是以高昂的功耗、计算以及数据代价为成本。反观人类大脑在执行相同甚至更复杂任务的同时,其能量消耗只有2W左右。相比之下,标准计算机仅分类识别1000种不同的物体时其功耗就高达250W。此外,广泛的连通性结构、功能化的组织层次以及时间依赖的神经元突触连接被认为是大脑高智力水平的三个重要的脑科学基础。而人工神经网络本质上是模拟大脑层级的简单结构,仅仅在空间维度上学习并表达特征。这也导致了ANN与已验证的大脑工作机制相比,其过多的模型参数反而显得过于冗余。由于上述两者在计算效率和功能结构上的巨大差异,脑科学和计算机科学领域的研究者开始探索新的类脑架构以实现人脑展现出的高智能、高能效特性。
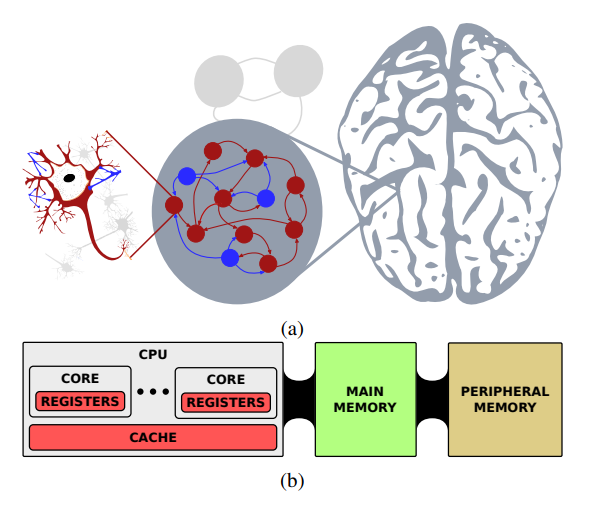
图1 人类大脑的神经元功能层次
1990 年Mead 首次在《Proceedings of IEEE》上提出神经形态(Neuromorphic)的概念[25]。神经形态芯片及系统的出发点,是借鉴大脑存储和计算相互依存的一体化特性,利用大规模可重构集成电路来模拟生物神经系统。但是由于当时AI技术的发展聚焦于人工神经网络的性能提升,而忽略了其在任务执行的功耗与时间代价。近年来,受生物大脑计算原语启发的神经形态计算在连续数据流处理上的可伸缩性、低功耗等方面具有极大的潜在优势,有望解决目前深度学习的高功耗、复杂计算量、低泛化性等问题。脉冲神经网络(Spiking Neural Network, SNN)作为第三代神经网络,通过模拟神经元动力学和突触连接特性,具有丰富的时空特征;同时,与ANN基于数值型计算模式不同,SNN的稀疏事件特性基于脉冲计算,能实现更高能效的计算,被认为是实现低功耗类脑芯片的最佳途径之一。因此,SNN逐渐成为神经形态硬件的基础模型,同时神经形态计算架构也成为研究热点。
三、类脑硬件架构技术
现有的神经形态芯片及系统,主要包括数模混合神经形态系统和全数字神经形态系统。数模混合神经形态系统在早期主要通过晶体管电路来模拟生物神经网络的神经动力学特性,如斯坦福大学的Neurogrid系统[21]、BrainScaleS[1]、耶鲁大学的DYNAPs系统[22]等,近年来,基于纳米忆阻器[2,3]结合的阵列能高效地实现模拟域的突触存储和积分运算,具有较大的潜力。虽然模拟技术能通过电路的电压、电流以及电导(或电阻)特性实现复杂的动力学模拟,但是其鲁棒性远不如数字电路,轻微的环境因素扰动往往会影响系统的正常工作状态。此外,EDA仿真工具链的缺乏也制约着模拟类脑计算系统的发展。因此基于可靠稳定的数字电路的神经形态系统成为当前类脑计算系统研究的主流。
类脑芯片架构是类脑芯片及其神经形态系统的灵魂所在,按照计算和存储的关系进行分类,目前神经形态架构主要包括以深度学习加速器为代表的存算分离架构、众核去中心化互联的近存计算架构,以及未来基于存算一体的众核架构。目前前两种类脑架构促进了基于ANN的深度学习处理器和基于SNN的神经形态芯片系统的快速发展。由于深度学习加速器完全在传统的冯诺依曼架构上进行特定计算的加速设计,采用集中式的管理控制,在形式上难以适应并行分布式的生物网络结构;同时需要在算法层面上优化并行计算以满足日益增长的高算力需求,这也是数值型ANN计算所必需的,例如寒武纪系列人工智能芯片(DianNao[4]、DaDianNao[5]以及PuDianNao[6]等)。由于深度学习加速器采用的ANN神经网络数值型计算范式和计算-存储分离架构,其性能依靠高速的总线中枢在计算单元集群和存储芯片之间传输数据。而人脑中的逻辑和认知通过大规模互联的神经元网络实现,因此基于深度学习加速器的神经形态系统难以和生物大脑的超强算力和超低功耗相提并论。
另一方面,神经形态系统旨在模拟生物大脑存储和计算一体化和分区协同等构造和功能特性,具有代表性的众核分布式并行的近内存架构能弱化存储和计算之间的鸿沟,同时其拥有的独立分布式存储实现了架构的去中心化,从而避免了大量数据访问冲突的带宽瓶颈问题。采用众核分布式并行架构的类脑系统包括英国曼彻斯特大学主导的SpiNNaker[20]、IBM的TrueNorth[18]、intel的Loihi[19]以及清华的Tianjic[7]类脑系统等。此外,神经形态硬件领域还包括一些小规模单核类脑架构。单核架构主要用于SNN的某些特性如学习规则、复杂神经元模型、稀疏异步等进行广泛探索,可以在宏观上把单核设计理解为多核设计的一个子集。多核类脑架构无论在规模上还是可重构性上都明显优于单核设计;同时多核设计通常具有强大和高效的构建编译工具链,与之对应的缺点就在于多核设计的复杂度明显高于单核设计。此外近内存架构虽然能缓解“存储墙”带来的延迟、功耗等问题,但实际上生物大脑的逻辑计算与认知记忆是一体的,对应的理想神经形态系统是存算一体的,因此未来的架构引入存算一体引擎(CIM, Computing In Memory)或将实现更加高效的类脑智能系统。
总体上,为了实现更加类脑的通用人工智能,需要解决两个关键科学问题:生物高能效计算模式的芯片架构仿生和生物高效在线学习方式的模拟。前者主要模拟生物大脑的低功耗、高效性以及大规模特性,主要通过主流众核架构实现,即计算核心与路由网络。而后者则更加注重生物神经网络在线学习的实现,即模拟生物大脑在复杂环境下的泛化性和学习进化。因此,下面将从众核架构与在线学习这两个方面展开架构的分析介绍。
3.1 类脑众核架构
典型的类脑众核架构如图2所示,设计的主要原则基于多个计算核心(Computing Core)和片上路由网络(Network on Chip, NoC)。计算核心实现模拟生物神经元的动力学行为,同时计算核心之间通过NoC完成数据和控制交互,共同完成复杂的类脑任务。然而,计算核心的资源始终会受到物理限制,因此可扩展性也是众核架构的主要特性,计算核心可以通过片上网络实现芯片内众核或者芯片间以至云边协同的扩展。此外,为了实现通用的人工智能,可重构性也是神经形态硬件研究者追求的共同目标。

图2 类脑主流架构(计算核心与NOC松耦合连接)
3.1.1 片上路由网络
生物的分布式并行计算能力要求使用高效的互联结构来实现大规模并行计算核心之间的通信,片上路由网络主要用于计算核心之间传递数据或者控制信息,同时并行计算核心自身也受到物理资源的限制,单个芯片不足以模拟整个大脑或者更大规模的生物神经网络,因此NoC在神经形态硬件的可扩展性、可靠性以及高能效特性方面都具有关键性作用。
上世纪90年代,NoC技术被提出并一直发展到现在,其核心思想是将计算机网络技术移植到芯片设计中来,从体系结构上彻底解决集中式总线架构带来的问题。在类脑众核架构中,片上网络借鉴多核SoC系统的通信架构思路,其中若干路由器根据适合的拓扑互联而成,每个路由器又相应地与类脑计算核心互联,根据底层网络拓扑和路由策略将数据包从源节点路由到目标节点,从而模拟大脑神经元互联结构和功能分区。
在可扩展性和可靠性方面,由于路由网络长程数据传输要求及时正确地交付传输的信息,目前路由网络主要采用数字电路技术实现。此外为了实现扩展特性,目前的类脑拓扑结构主要采用Mesh或者Tree结构,不过在维度上和可扩展性上有部分差异,例如SpiNNaker [20]采用六角形拓扑结构互连以构成庞大的神经形态网络,主要利用路由容错机制实现基于ARM计算核阵列的大规模生物神经网络模拟。TrueNorth [18] 的总体架构由异步计算核心通过二维Mesh路由形成规模神经形态网络,这一思路也被之后出现的多款类脑芯片所使用。英特尔推出的神经形态自学习芯片 Loihi [19],总体可支持模拟 13 万个神经元和 1.3 亿个突触。其核心Mesh阵列之间采用异步片上网络通信,通过片上网络协议和分层寻址的方式可分别支持扩展到4096 个片上神经元核和总体 16384 个芯片。后续的工作Loihi-2在Loihi-1基础上升级成3D-Mesh结构,拥有更多的路由自由度。而清华的 Tianjic [7]也采用了同TrueNorth和Loihi类似的Mesh计算阵列思想,但计算核心和路由都采用同步的设计方法。表1中总结了主流大规模类脑架构中采用的路由特性,可以看出异步Mesh是大多数类脑架构采用的路由设计思路。Mesh路由的优势在于兼具可扩展性和可靠性,设计者可利用成熟的维序路由等优化算法缓解系统的通信拥塞、死锁等问题(图3),同时可以通过路由表的重构实现复杂的网络拓扑结构。不过,Tree路由、六角形路由等也在局部通信域内具有优势,因此Mesh全局路由与Tree路由结合可以形成混合路由(如图4所示),提高局部的通信效率同时减少全局的通信量。
表1 大规模类脑架构路由网络比较
| 神经形态硬件 | 时间 | 数模
特性 |
路由拓扑 | 模型 | 同步异步
(路由网络) |
单芯片阵列 |
| SpiNNaker [20] | 2013 | 数字 | Hexagon | SNN | 异步 | 18 |
| Neurogrid [21] | 2014 | 混合 | Tree(板级) | SNN | 异步 | 1 |
| TrueNorth [18] | 2015 | 数字 | 2D Mesh | SNN | 异步 | 4096 |
| Loihi [19] | 2018 | 数字 | 2D Mesh | SNN | 异步 | 128 |
| DYNAPs [22] | 2018 | 混合 | Mesh(板级)Tree(片内) | SNN | 异步 | 4 |
| Tianjic [7] | 2019 | 数字 | 2D Mesh | Hybrid | 同步 | 156 |
| MorphIC [23] | 2019 | 数字 | 2D Mesh | SNN | 异步 | 4 |
| Chen et al [8] | 2019 | 数字 | 2D Mesh | SNN | 同步 | 64 |
| BiCoSS [12] | 2020 | 数字 | Tree(板级) | SNN | 同步 | 64-256 |
| Cho et al [9] | 2019 | 数字 | 2D Mesh | SNN | 异步 | 16 |
| Novena [10] | 2020 | 数字 | 2D Mesh | SNN | 异步 | 16 |
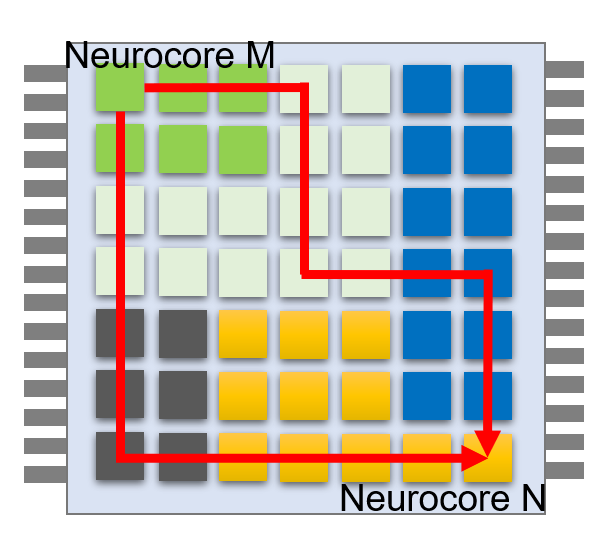
图3 Noc路由算法
图4 Mesh-Tree混合路由架构
此外,复杂的系统需要更大的通信代价,除了路由资源的消耗外,路由所需的功耗也不容小视。目前两种可能的方案是通过异步捆绑数据路由和功耗自适应路由实现。前者采用事件驱动的方式,例如Intel的loihi[19]就采用了这样的设计风格,根据异步路由的算法时间步来同步计算核心中的计算。后者则通过统计计算核心之间的通信量来评估路由的工作情况,从而利用门控时钟减少全局数字时钟路由带来的额外功耗损失。这两种方式都能在一定程度上减少大规模片上路由带来的功耗,并且在一定程度上模拟生物神经网络的稀疏脉冲激发特性。
3.1.2 高能效计算核心
计算核心作为众核计算架构中承担计算角色的模块,其效率和功耗直接决定类脑计算芯片及系统的性能。最初的尝试主要以模拟生物神经网络为目的,例如SpiNNaker 类脑架构[20],主要目的是仿真相当于1%人脑规模的神经网络,其计算核心被称为CMP(Chip Multiprocessors),能够仿真包括LIF、Izhikevich以及HH等模型在内的多种神经元动力学模型,这得益于其计算核心采用基于冯诺依曼架构的ARM计算平台,因此缺点也体现在其计算效率和功耗的限制上。近年来,计算核心的研究主要集中在基于特定脉冲神经网络模型的计算优化,追求高能效的神经网络模拟计算。例如Intel Loihi[19]以及后续的Loihi2在架构上融合神经形态计算核和x86核心,并使用同步和异步结合的设计思路平衡计算能效和EDA设计工具的支撑能力。Loihi 的神经元计算核心实现了可编程脉冲神经元计算核心,多个计算核心通过片上网络 NoC 实现互联。Loihi及Loihi2芯片在架构上侧重底层神经元的行为模型,但上层由有限的多个x86核进行集中式的协同管理,对不同粒度的类脑功能分区协同以及多个层次的在线学习算法支撑有限,缺少更大尺度上的架构可塑性和演化能力。清华的Tianjic[7]主要的创新点在于统一计算平台,其通用计算核心包含可配置MUX的ANN和SNN双模计算路径,从而实现ANN-SNN异构融合,其计算核心的详细架构如图2所示。这样的好处显而易见,通过挖掘了ANN算子和SNN算子的共通之处,并用可复用的计算架构进行融合,打破ANN和SNN不兼容的鸿沟。缺点就在于单个计算核心内部只有16个MAC进行并行计算,因此在一定程度上为灵活性牺牲了算力性能。这些计算核心架构存在共同的一个缺点就在于不能兼容新的SNN模型与算法,因为它们的计算路径相对固定,以减少映射的难度和约束要求。而随着类脑计算领域研究的进一步深入,未来新的模型与算法将可能被发掘更新,一个典型的例子就是存内计算引擎的发展,虽然这类专用的存内计算单元能效极高,但灵活性差,对未来新的算法难以快速支撑。因此为存内计算技术的扩展提供兼容接口,保证计算的高效性和多样性对于类脑架构的关键作用不言而喻。
类脑芯片旨在模拟生物大脑特性,除了SNN模型自身带来的数据时空关联特性之外,计算应该具有异步低功耗特性,这也是类脑的关键特性之一。例如,IBM的TrueNorth 芯片[18]是异步计算核心的一个实现例子。该芯片的核心基于脉冲神经网络的异步电路实现,系统架构设计原则是“事件驱动”, 即电路仅仅在脉冲出现的局部区域被激活与执行动作。电路架构适应脉冲神经网络的连接稀疏性和脉冲稀疏性,它的缺点是电路架构和特定的神经元模型绑定、失去了灵活性。另外基于纯异步的电路设计受限于 EDA 工具的支持,规模化设计难度高,因此更多采用数字数据捆绑的形式实现异步,比如单核的ODIN[24]、ReckOn[11]以及多核的MorphIC[23]中实现的异步AER协议。除了上述介绍的部分类脑架构之外,表2中还比较了其他类脑架构中的计算核心特性。
表2 类脑架构计算核心特性比较
| 神经形态硬件 | 神经元 | 突触
容量 |
同步异步
(计算核心) |
工艺 | 在线学习 |
| Neurogrid [17] | 64k | 100M | – | 180nm | 离线 |
| DYNAPs [18] | 1024 | 64k | – | 18nm | 离线 |
| SpiNNaker [16] | 18k | 18M | 同步 | 130nm | 在线,基于STDP学习 |
| TrueNorth [14] | 1M | 256M | 异步 | 28nm | 离线 |
| Loihi [15] | 128k | 128M | 异步 | 14nm | 在线,基于可编程STDP |
| Tianjic [7] | 39k | 9.75M | 同步 | 28nm | 离线 |
| ODIN [24] | 256 | 64k | 同步 | 28nm | 在线,SDSP算法 |
| MorphIC [23] | 2k | 528k | 同步 | 65nm | 在线,s-SDSP算法 |
| ReckOn[11] | 272 | 132k | 同步 | 28nm | 在线,改进e-prop算法 |
| Chen et al [8] | 4k | 1M | 同步 | 10nm | 在线,基于STDP算法 |
| Cho et al [9] | 2k | 149k | 同步 | 40nm | 离线 |
| Novena [10] | 2k | 256k | 同步 | 40nm | 离线 |
3.2 在线学习能力
生物的在线学习能力是类脑芯片及系统中高智能的核心体现。一些数模混合系统如Neurogrid[21]、ROLLS[13]等利用模拟电路研究了以STDP、STDP简化版本SDSP算法等以无监督学习为主的突触可塑性学习机制。由于模拟硬件的电气特性限制,很难实现复杂的学习算法,并且学习算法在规模较大的模拟计算核心上实现时,也不可避免地使用数字电路如FPGA等进行路由,因此目前实现新的学习算法主要依靠数字电路。SpiNNaker[20]是早期支持在线学习的类脑计算平台,由于采用的商用ARM核具有编程灵活性,除了前面提及的多种神经动力学模型之外,还支持了基于STDP学习规则的突触学习功能。通过共享的片外DRAM权重系数存储,前后端脉冲能够实时实现权重更新,从而实现在线无监督学习。loihi[19]的每个计算核心都包含一个学习引擎,支持利用基于STDP及其变种算法的可编程学习规则来更新突触权重,具备一定的学习能力和可编程灵活性。此外,为了支持多种学习规则,FlexLearn[14]融合了包括长/短时程可塑性在内的17种突触学习规则,同时进行了数据通路优化以提高在线学习效率。ODIN[24]芯片使用了和其数模混合版本的ROLLS[13]类脑芯片相同的长时程突触可塑性规则,即脉冲驱动突触可塑性(SDSP)学习。ODIN的研发团队又提出MorphIC[23]进行改进,其中突触的学习规则变成了随机脉冲驱动突触可塑性(s-SDSP),并且利用离线学习3层MLP的手写数字识别,对比在线学习的八分类模式识别以体现其在线学习功能。此外一些工作也积极探索了生物在线学习能力的模拟,如Cordic-SNN [15],该工作通过FPGA硬件实现STDP(脉冲突触可塑性)来模拟随机输入在线学习时呈现的双模分布。
表2中总结了目前一些类脑硬件实现的在线学习方法,可以看出目前的类脑架构主要采用简单的STDP及其变种学习算法。STDP规则等无监督学习算法在众核计算阵列实现方面具有硬件友好性,虽然在面对浅层网络无监督学习时能取得一定的效果,但其面对深层网络时缺乏复杂特征的提取能力,无法满足诸如目标检测、自然语言处理等传统的机器学习或模式识别的任务,所以新的在线学习无监督或有监督学习算法的支持和兼容将会成为类脑计算平台竞争的主要阵地。近期的一款循环脉冲神经网络 (Recurrent Spiking Neural Networks, RSNN) 处理器芯片ReckOn [11],能在几秒钟内以毫秒的时间分辨率进行脉冲突触在线学习,基于自适应LIF神经元模型和改进的局部时间反向传播e-prop算法[25],大大减少计算和内存需求,但其仅实现了比较浅层的循环脉冲网络。此外Park等人[17] 提出了通过简化的脉冲反馈的监督学习SD算法[16],实现了两个隐藏层MLP的学习,相较于推理计算,融合在线学习仅增加7.5%的功耗代价而实现了在MNIST上97.83%的分类正确性,但目前该硬件仍无法应用于CNN,同时在深层全连接网络的应用上也具有较大的限制。
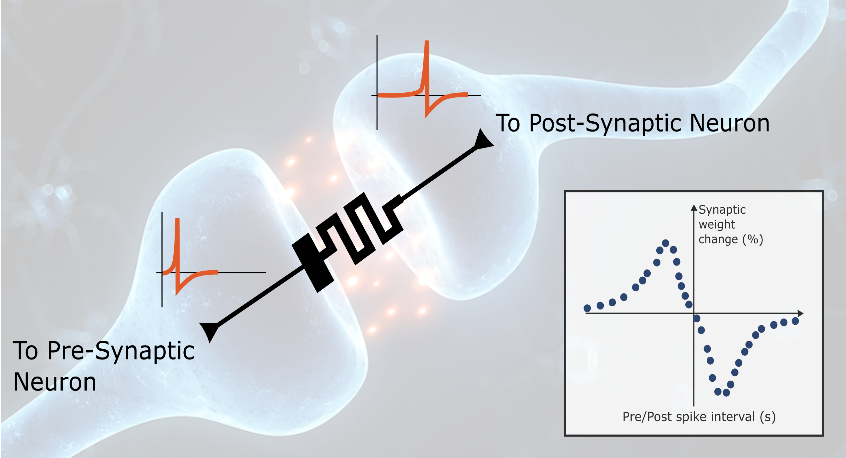
图5 突触可塑性连接
在线学习算法的主要考虑是潜在的训练能量开以及机器学习任务的性能。无监督的神经形态算法,如STDP等依赖于局部的动力学信息来调整其突触权重,因此具有较小的路由资源和功耗代价;而基于BP算法等利用全局误差反向传播,在硬件实现复杂度和代价上都具有一定的限制。此外,生物在线学习能力应该是层次化的,一个可能的角度是通过微观-介观-宏观层面上,在类脑芯片中实现数据关联性的神经元激活更新、突触权重和连接可塑性(图5)以及多核分区协同计算,从而提高类脑芯片的泛化能力和环境适应能力,这再次体现了类脑计算平台对于兼容未来的重要性。因此支持在线学习的类脑硬件架构需要算法和架构的共同努力,在算法上开发局部和全局误差信息结合的学习算法,在架构上实现高效的在线学习硬件实现方案。
四、总结
本文分析介绍了大规模众核类脑架构技术发展现状,展望了未来支持在线学习或将成为类脑系统高智能代表的关键特性。类脑智能有望从根本上改变处理信号和数据的方式,目前已经成为新一代人工智能角逐的主要阵地,为了构建高能效、高智能的支持在线学习的类脑系统,仍需要神经形态计算社区的持续努力,以满足无人驾驶、机器人作业等智能应用需求,最终实现通用人工智能的宏伟蓝图目标。
参考文献
- Schemmel J , D Brüderle, A Grübl, et al. AWafer-Scale Neuromorphic Hardware System for Large-Scale Neural Modeling[C]// Circuits and Systems (ISCAS), Proceedings of 2010 IEEE International Symposium on. IEEE, 2010.
- Fu-Dong Wang, Mei-Xi Yu, Xu-Dong Chen*, Jiaqiang Li, Zhi-Cheng Zhang, Yuan Li, Guo-Xin Zhang, Ke Shi, Lei Shi, Min Zhang*, Tong-Bu Lu*, Jin Zhang*. Optically modulated dual‐mode memristor arrays based on core‐shell CsPbBr3@graphdiyne nanocrystals for fully memristive neuromorphic computing hardware. SmartMat.2023;1,117-129.
- Huang J N , Wang T , Huang H M , et al. Adaptive SRM neuron based on NbO_(x) memristive device for neuromorphic computing[J]. 2022(002):001.
- Chen T, Du Z, Sun N , et al. DianNao: a small-footprint high-throughput accelerator for ubiquitous machine-learning[C]// International Conference on Architectural Support for Programming Languages & Operating Systems. ACM, 2014.
- Chen Y, Tao L, Liu S , et al. DaDianNao: A Machine-Learning Supercomputer[C]// 2014 47th Annual IEEE/ACM International Symposium on Microarchitecture.
- Liu D , Chen T , Liu S , et al. PuDianNao: A Polyvalent Machine Learning Accelerator[J]. ACM SIGPLAN Notices, 2015, 50(4):369-381.
- Pei J, Deng L, Song S , et al. Towards artificial general intelligence with hybrid Tianjic chip architecture[J]. Nature, 2019, 572(7767):106.
- G. K. Chen et al., “A 4096-Neuron 1M-Synapse 3.8- pJ/SOP Spiking Neural Network With On-Chip STDP Learning and Sparse Weights in 10-nm FinFET CMOS,” in IEEE Journal of Solid-State Circuits, vol. 54, no. 4, pp. 992-1002, April 2019.
- S. -G. Cho et al., “A 2048-Neuron Spiking Neural Network Accelerator With Neuro-Inspired Pruning And Asynchronous Network On Chip In 40nm CMOS,” 2019 IEEE Custom Integrated Circuits Conference (CICC), 2019, pp. 1-4.
- V. P. Nambiar et al., “0.5V 4.8 pJ/SOP 0.93μW Leakage/core Neuromorphic Processor with Asynchronous NoC and Reconfigurable LIF Neuron,” 2020 IEEE Asian SolidState Circuits Conference (A-SSCC), 2020, pp. 1-4
- C. Frenkel and G. Indiveri, “ReckOn: A 28nm Sub-mm2 Task-Agnostic Spiking Recurrent Neural Network Processor Enabling On-Chip Learning over Second-Long Timescales,” 2022 IEEE International Solid- State Circuits Conference (ISSCC), 2022, pp. 1-3, doi: 10.1109/ISSCC42614.2022.9731734.
- Yang S, Wang J, Hao X , et al. BiCoSS: Toward Large-Scale Cognition Brain With Multigranular Neuromorphic Architecture[J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, PP(99):1-15.
- Qiao N, Mostafa H, Corradi F , et al. A Re-configurable On-line Learning Spiking Neuromorphic Processor comprising 256 neurons and 128K synapses[J]. Frontiers in Neuroscience, 2015, 9(141).
- Baek E , Lee H , Kim Y , et al. FlexLearn: Fast and Highly Efficient Brain Simulations Using Flexible On-Chip Learning[C]// the 52nd Annual IEEE/ACM International Symposium. ACM, 2019.
- Heidarpur M, Ahmadi A , Ahmadi M , et al. CORDIC-SNN: On-FPGA STDP Learning With Izhikevich Neurons[J]. IEEE transactions on circuits and systems, I. Regular papers, 2019(7):66.
- J. Guerguiev, T. P. Lillicrap, and B. A. Richards, “Towards deep learning with segregated dendrites,” ELife, vol. 6, Dec. 2017, Art. no. e22901.
- Park J, Lee J , Jeon D . A 65-nm Neuromorphic Image Classification Processor With Energy-Efficient Training Through Direct Spike-Only Feedback[J]. IEEE Journal of Solid-State Circuits, 2019, PP(99):1-12.
- Akopyan F, Sawada J, Cassidy A , et al. TrueNorth: Design and Tool Flow of a 65 mW 1 Million Neuron Programmable Neurosynaptic Chip[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2015, 34(10):1537-1557.
- Davies M, Srinivasa N , Lin T H , et al. Loihi: A Neuromorphic Manycore Processor with On-Chip Learning[J]. IEEE Micro, 2018:82-99.
- Painkras, E, Plana, et al. SpiNNaker: A 1-W 18-Core System-on-Chip for Massively-Parallel Neural Network Simulation[J]. IEEE Journal of Solid-State Circuits, 2013, 48(8):1943-1953.
- Benjamin B V, Gao P , Mcquinn E , et al. Neurogrid: A Mixed-Analog-Digital Multichip System for Large-Scale Neural Simulations[J]. Proceedings of the IEEE, 2014, 102(5):699-716.
- Moradi S, Qiao N , Stefanini F , et al. A Scalable Multicore Architecture With Heterogeneous Memory Structures for Dynamic Neuromorphic Asynchronous Processors (DYNAPs)[J]. IEEE Transactions on Biomedical Circuits and Systems, 2018, 12(99):106-122.
- Charlotte F, Jean-Didier L , David B . MorphIC: A 65-nm 738k-Synapse/mm $^2$ Quad-Core Binary-Weight Digital Neuromorphic Processor With Stochastic Spike-Driven Online Learning[J]. IEEE Transactions on Biomedical Circuits and Systems, 2019, 13(5):999-1010.
- Frenkel C, Lefebvre M , Legat J D , et al. A 0.086-mm$^2$ 12.7-pJ/SOP 64k-Synapse 256-Neuron Online-Learning Digital Spiking Neuromorphic Processor in 28-nm CMOS[J]. IEEE Transactions on Biomedical Circuits and Systems, 2019, 13(1):145-158.
- Mead C. Neuromorphic electronic systems. Proceedings of the IEEE, 1990, 78(10): 1629-1636


{kind=link}
{kind=link}
{kind=link}
{kind=link}