在线持续学习简介
在线持续学习是深度学习领域的一个重要研究方向,旨在解决传统深度学习方法在处理动态数据时的局限性。传统的深度学习算法通常在静态的数据集上进行离线训练,将训练后的模型部署到实际应用中,并在部署后不再更新模型。然而,现实世界中的数据往往与训练数据集不完全相同,且是动态变化的。新的数据不断产生,旧的数据可能过时或失效。传统的静态模型往往无法适应这种变化。
举个例子来说,当我们将源域上训练的深度神经网络部署到测试环境,即目标域时,目标域上的模型性能会因为域偏移而恶化。在自动驾驶中,一个训练完成的模型可能由于天气、运行区域、传感器等的不同而在测试时表现出显著的性能下降。实际应用中,测试集与训练集不完全匹配是十分普遍的。并且由于难以预知环境将会发生怎样的变化,需要在与环境不断交互的过程当中,学习到在新的场景下更准确的数据表示,从而保持任务的性能。这就是一个在线持续域适应的问题。
片上持续在线学习是SNN的一个具有潜力的应用场景。
- 要实现端侧的在线适应,就需要在内存、功耗等的限制下进行在线训练。低功耗的端侧学习正是SNN的主要优势之一。
- 现实生活中的数据是流式传入的。基于一个个传来的数据进行模型更新,与人和动物在不断变化的自然环境中进行学习的过程较为类似,是一种理想的适应方式。而由于SNN需要为每个样本维护一组膜电位,增加batch size会近乎成倍增加资源占用量。所以实际部署到片上时,单样本的适应过程也是对硬件友好的。
但是实际上基于单样本的持续在线适应是一个较为困难的任务。下面章节中将介绍一些单样本持续在线适应的挑战,以及一些小批量/单样本适应相关的方法。
基于单样本的在线持续域适应的挑战
基于小批量/单样本的在线持续域适应面临一系列的挑战。首先,单样本更新导致模型的归一化统计参数难以准确估计。模型的归一化统计参数是指,由一个批量中所有样本的特征计算出的均值与方差。批归一化统计(Batch Norm)是目前深度学习中非常普遍的一种做法,可以缓解梯度爆炸/消失、减少过拟合风险、增加模型收敛速度、减少模型对于训练参数的依赖等。基于少量/单个样本计算出的统计信息是有偏的,而基于有偏的统计参数计算的归一化值会不准确,导致模型性能下降。同时,基于单个样本产生的损失更新模型会导致模型更新不稳定。由于样本间质量参差不齐,不同样本的特征很可能有较大差异,导致产生的模型更新方向不稳定。
基于流式样本进行长时间的在线自适应也会面临长时间无监督训练造成错误累积与灾难性遗忘问题。由于在测试阶段没有标签,需要借助最小化熵等无监督损失进行训练,模型无法确定更新方向的准确性。在长时间自适应时,由于模型下一时刻的预测值依赖于当前输入以及之前所有时刻的梯度,一旦前一时刻的模型更新方向错误,会直接导致下一次的模型预测值不准确、从而造成下一次的更新错误累积。而一旦错误累积问题变得十分严重,便会导致模型更新大幅度偏离源模型参数,彻底忘记之前学习过的知识,即灾难性遗忘问题。
传统的深度学习中,我们预先收集好了所有的训练数据,在训练的时候将其打乱。样本分布大多是独立同分布的。然而现实生活中,数据是流式输入、不断演变的,通常具有时间相关性,输入的独立同分布假设往往不成立。现实生活中的非独立同分布数据流加剧了模型的灾难性遗忘问题。
小批量/单样本更新的方法
本章节中,介绍一些小批量/单样本更新的方法。
3.1 基于Batch Norm层的适应
目前一种普遍的测试时间自适应方法是重新校准batch norm层的统计参数。具体如图1所示,首先基于当前batch的目标域数据重新计算batch norm层的统计参数(而不是直接使用从训练训练数据中学习到的统计参数)。然后,基于测试样本,针对特定优化目标调整归一化后的仿射参数(即 γ和β ),以完成模型的更新。Tent[1]提出的最小化熵优化目标由于其有效性而被广泛使用。

图1 重新校准BN层统计参数,并仅更新仿射参数[1]

式(1): BN层特征计算公式; 式(2): BN层统计参数均值与方差的计算公式
实际上,仅是通过BN层统计参数的重计算便能大幅提升自适应的性能。图2展示了不同情况下图像的特征分布。方法(a) Source是采取源域统计量与源模型仿射参数,方法(b) BN是采取目标域统计量与源模型仿射参数。结合式(1)来看,方法(b)作归一化时,其µ 与 σ来自目标域数据,而γ 与 β来自源域。方法(c) Tent是采取目标域统计量,并基于最小化熵更新仿射参数。即在方法(b)基础上,基于目标域数据更新γ 与 β 。方法(d) Oracle采用目标域数据监督训练模型,是我们所期望的特征分布。
四张子图中,最后侧的黄色部分均是没有噪声的图像在源域模型上的特征分布。如图2(a)所示,如果直接将目标域数据应用到源域模型上,模型提取的特征分布会与未加噪的数据有较大的不同,从而造成性能的下降。如图2(b)所示,方法(b)调整了带噪数据特征分布的位置和宽窄。可以发现仅是调整BN层参数后,带噪数据的特征分布就已大幅接近目标域数据监督训练的结果。方法(a)的错误率可能高达80%多,而调整统计参数为目标域数据统计参数后,可以把错误率降到20%左右。方法(c)在(b)的基础上,对数据分布的形状也做出了一定的调整,可以令错误率再下降大概1-3个百分点。

图2 带有高斯噪声的CIFAR100-C图像的特征分布[1]
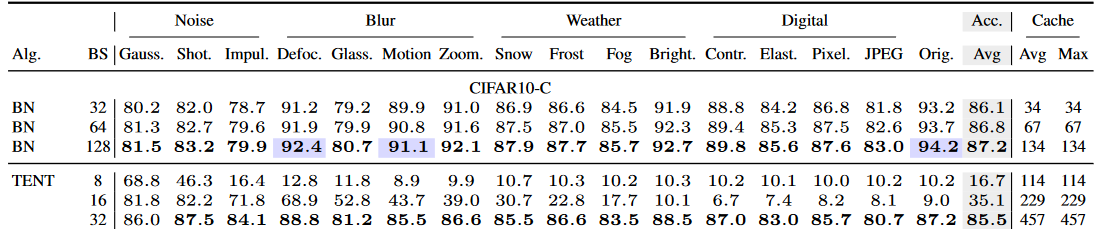
实际上目前以基于BN的模型为预训练网络进行适应的方式,都极大依赖于BN层参数的调整。但是这种方式的缺点也显而易见。因为要对统计参数有一个校准的估计值,要求一个batch的中有较多的样本。如表1所示,当batch size为32的时候,Tent准确率为85.5。但是batch size降低到16、8的时候,准确率会降低到35.1、16.7。同时可以观察到,在batch size为16、8的时候,发生了灾难性遗忘。由于较小的batch size估计的统计参数不准,仅使用未加任何修改的Tent的话,是难以在小样本、单样本上进行适应的。这实际上不符合现实生活中数据流式输入的场景。但是由于目前的主流预训练模型都是基于BN实现的,后续很多实现小样本、单样本自适应的方法其实是基于改进的BN统计参数估计方法。
表1 不同batch size下Tent的性能[2]

- 基于指数滑动平均的统计量估计方法
第一种方式是测试时基于指数滑动平均来更新统计量。如式(3)所示,设∅为BN层中的均值和方差组成的元组[µ , σ], ∅t‘ 为从第𝑡 小批量计算的统计参数,∅t为适应到第 𝑡 小批量时,计算归一化使用的统计参数。即用累积计算的统计参数与当前小批量实际统计参数的加权和表示当前小批量的归一化时所用的统计参数。

为了自适应地调整滑动平均的参数,首先利用KL散度计算分布∅t-1与 ∅’t 之间的距离,用D表示,如果分布距离小,表明当前小批量样本发生的域偏移程度较小,滑动平均的权值 β 也相对较小。而如果发生了突然的较大的域偏移,比如车突然开入隧道,算出的分布距离会变大,从而对于当前批量的权重会变大,就可以更快地调整到目标域的分布。在实际估计的时候,β 是逐层估计的,因为不同层的分布会有不同程度的偏移。直观上,当浅层在校准后对齐良好时,深层应该对齐得更好。
如表2所示,在将原始BN模块替换为改进后的模块(MECTA)[2]后,将Tent在batch size为16时的准确率从35提升到了71。当然MECTA中除了用到所介绍的自适应滑动更新BN层的方法外,还采取了稀疏剪枝、按需训练一类的策略,提升效果是共同作用下的结果。
但是这种方法实际还是依赖于小批量的统计数据分布,会导致当batch size进一步减小时,当前小批量的计算的分布统计参数漂移大,导致性能下降。但是其提出的从数据中动态估计滑动平均参数以及剪枝的思想是可以借鉴的。
表2 MECTA对于Tent的提升作用 [2]


2. 利用数据增广估计单样本的Batch Norm统计参数
另一种方法是利用数据增广估计单样本的BN参数。如图3所示,谷歌斯坦福在2022年提出AugBN[3],借助单样本的多个增强估计了单样本的BN层统计参数。它实际上是对一个样本施加多次数据增强,然后用原样本与增强后的样本一起计算BN统计参数,再与源模型参数加权平均。前面介绍的的MECTA是在batch的维度上面滑动平均,而AugBN是在源域统计数据单样本和多个增强的统计数据上面加权平均。

图3 AugBN: 利用数据增广估计BN层统计参数[3]
由于数据增强样本的分布难以控制,所以不是为所有的增广样本分配与原样本相同的权重 ,把增广样本的权重设置为1/2n,其中n为数据增强数目。实际实验时,n=2,即对单样本进行两次增强;k=5, m=5,就是说每次用五种数据增强的组合作用到x上。
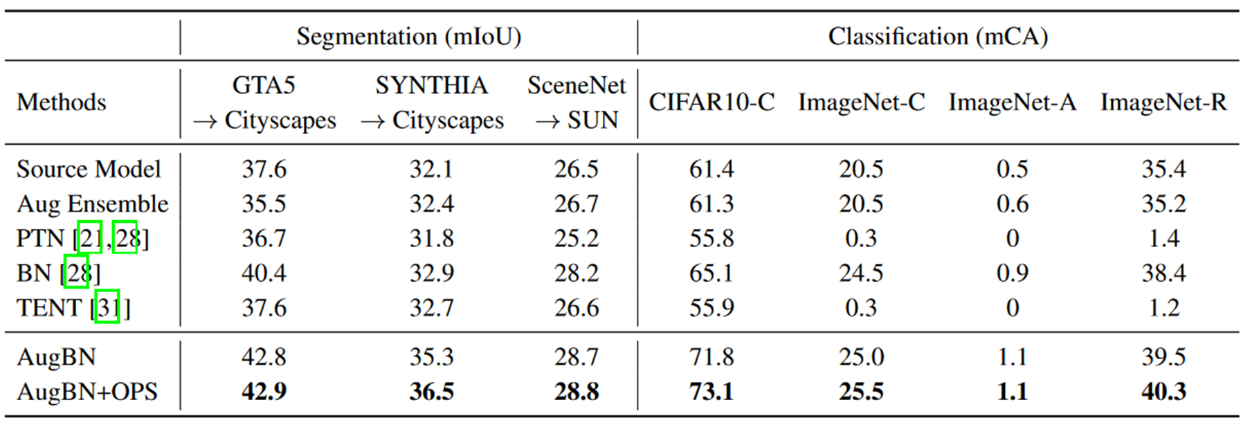
由于AugBN需要跑次不同的先验值,实际使用时,,再用熵最小的top3结果进行投票。就是说,AugBN实际只解决了流式样本更新时每次只有单个样本可用的问题。但实际上它需要有多次的前向过程,增加了推理过程的计算量。但是之所以需要那么多次前向过程,是因为其本身是一种非参数化的方法,需要依据多次迭代的投票找出分类。如果结合在线适应的一些无监督loss可能可以减少前向的次数。表3展示了AugBN在各数据集上的性能,在分类方面,与直接使用源模型相比,AugBN在CIFAR-10-C上取得了17 %的相对提升,并且与现有的方法相比也有不错的表现。但在ImageNet-C上的准确率仍仅有25%左右。
表3 AugBN 在各数据集上性能
3. 利用Instance Norm修正Batch Norm统计参数
NIPS2022年发表的NOTE提出了一种利用instance norm (IN)修正batch norm值的方法[4]。在介绍NOTE之前,我们来大致了解一下不同的norm方法。如图4所示,Batch Norm是针对一个channel计算当前channel的均值、方差进行标准化,Layer norm是针对单个样本的所有channel进行均值、方差的计算,Instance Norm是针对单个样本、单个channel的特征图进行标准化,Group Norm是针对单个样本的成组特征进行标准化。
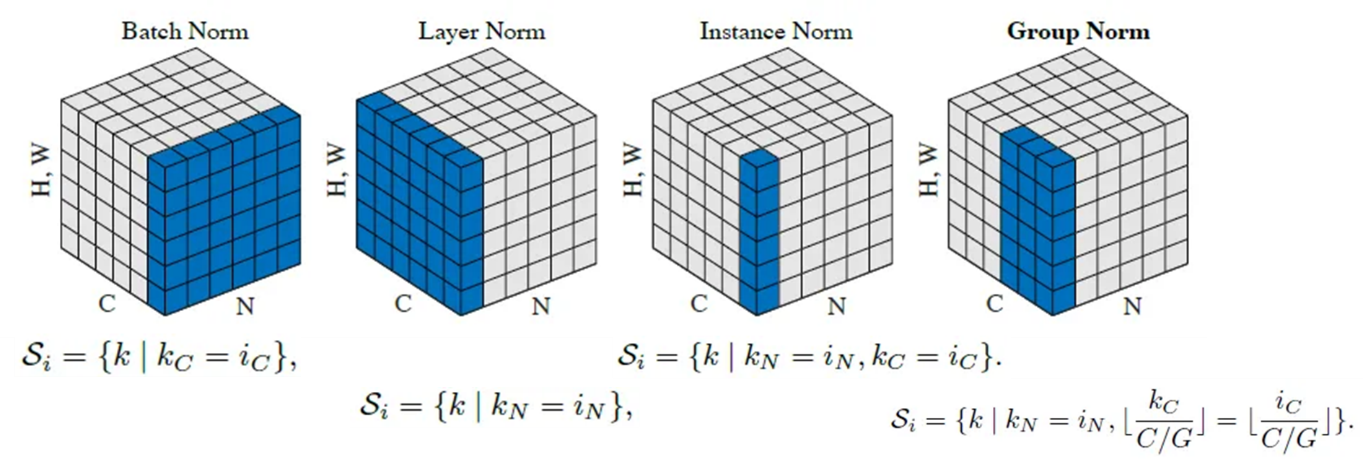
图4 不同的归一化方法图示[6]
NOTE旨在解决流式输入样本的时间相关性问题,当样本间并非独立同分布(如图5所示)时,在所有样本上计算统计量会损害有用信息,造成准确率的下降,因而采用IN层统计参数对BN层统计参数进行修正。

图5 非独立同分布流式样本示意图[4]
具体来说,NOTE提出的均值、方差估计公式如式(4)所示。
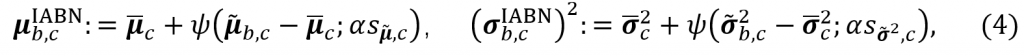
其中,$\overline{\mu}_c$、$\overline{\sigma}_c ^2$为BN层的统计参数,而$\tilde{\mu}_{b,c}$、$\tilde{\sigma}_{b,c} ^2$则为IN层的统计参数,$s^2_{\tilde{\mu},c}$为$\tilde{\mu}_{b,c}$的方差,$s^2_{\tilde{\sigma}^2,c}$为$\tilde{\sigma}_{b,c} ^2$的方差, $\psi(x ; \lambda)= \begin{cases}x-\lambda, & \text { 当 } x>\lambda \\ x+\lambda, & \text { 当 } x<-\lambda \\ 0, & \text { 其他 }\end{cases}$ 为软阈值公式,$\alpha$为超参数,用于确定 BN 统计信息的置信水平。高$\alpha$值更依赖于学习的统计信息,而低$\alpha$值的则偏向于从实例测量的当前统计信息。NOTE用IN修正BN统计量的同时,还使用了指数滑动平均更新BN的方式,如式(5)所示。
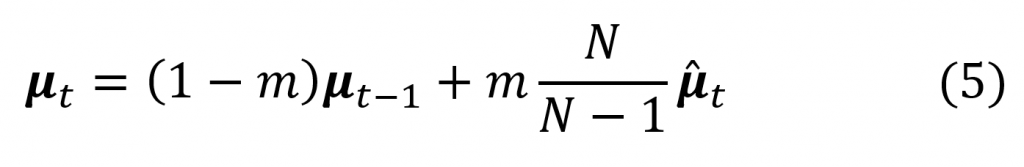
如表4所示,在时间相关性情况下,NOTE的表现明显优于其他方法。如图6所示,样本分布偏移和batch size不会显著影响NOTE的性能。
表4 NOTE在各数据集上性能
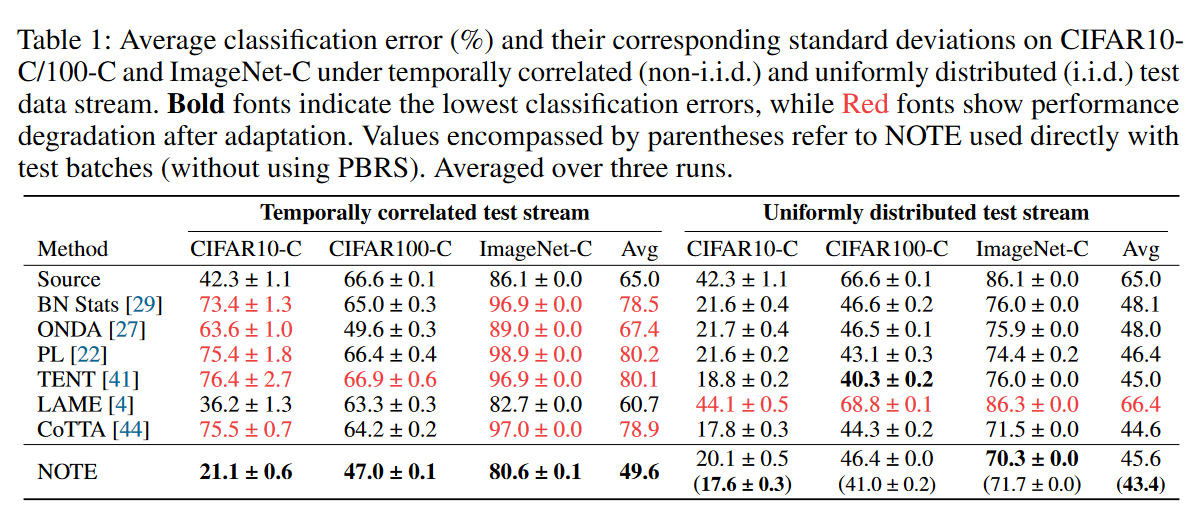

图6 不同样本分布偏移程度与batch size下各算法的性能
3.2基于Group Norm层的适应[5]
从前面几种方法介绍中也可以看出,基于BN层的自适应有以下几个问题:
- BN统计量代表了一个分布,理想情况下每个分布都应该有自己的统计量。简单从小批量测试样本中估计多个分布的共享BN统计量,必然无法很好地匹配每个分布,从而损害性能。
- 估计统计量的质量依赖于批量大小,很难使用小批量的样本对其进行准确估计。
- 不平衡的标签偏移导致BN统计偏向数据集中的某些特定类别。
正是由于基于BN方法的这些缺陷,前面所介绍的方法还需要额外考虑类别不均衡,或是时间相关性较强等情况下BN估计的改良。于是南方科技大还有腾讯团队提出了基于Group Norm (GN) 进行单样本的在线自适应的方式,称为SAR。因为无需较大的batch size估计BN值,除了可以做到单样本,还可以解决混合域数据分布和不均衡标签分布下的适应问题。但是如果单纯使用最小化熵损失来更新GN层的参数,在噪声较大的情况下很容易发生崩溃现象。即随着适应的进行,模型倾向于将所有输入样本预测到同一个类中(即使样本本身的标签是多样的)。如图7所示,图7(a)和(b)记录了在线适应过程中的模型预测。可以看到在数据噪声较大的情况下,在几十个batch之后,模型会将所有样本预测到一个类里,即使样本的标签是多样的。而噪声较小时,类别较为均匀。说明噪声较大时,模型发生了崩溃。图7 (c)说明了梯度范数在有无模型崩溃的情况下的演化过程。可以看到模型崩溃的节点上,有样本产生了较大的梯度。图7 (d)研究了样本熵与梯度范数之间的关系。理想状态下,我们只期望在Area 3范围内进行更新。

图7 测试时间熵最小化自适应的失效案例分析
基于此,作者将三种策略用于SAR中以提升基于GN进行自适应的性能:
- 可靠熵最小化:去除部分梯度较大的样本以及不可靠样本,即去除Area 1与Area 2中的样本。
- 模型锐度优化:优化模型锐度使模型具有平坦的极小值,从而增强其泛化能力,使模型对样本中产生的某些噪声梯度具有更高的鲁棒性,即使模型对Area 4 中样本贡献的大梯度不敏感。
- 部分恢复原模型参数:检测到模型有发生崩溃的风险后,即恢复原模型参数,重新开始适应,从而减轻错误累积以及灾难性遗忘的影响。
不同方法在ImageNet-C(severity 5)上单样本适应的性能如表5所示, 总体上来说,SAR在达到较高准确率的同时,具有较低的复杂度,并且不需要额外的数据。与方法[3]比,在ImageNet-C上达到了更高的准确率。
表5 不同方法在ImageNet-C(severity 5)上单样本适应的性能
总结
本文主要介绍了目前小批量/单样本在线自适应的一些挑战和可能的解决方法。具体来说,介绍了
- 基于BN层进行自适应的方法,通过
- 在小批量数据上滑动平均更新BN层统计参数
- 利用单样本的多个增强估计单样本的统计参数
- 利用实例维度的特征修正BN层统计量
- 基于Group Norm的单样本自适应方式,通过可靠熵最小化、模型锐度优化以及部分恢复原模型参数等方式提升自适应的性能。
综合而言,在标签和输入分布难以预知的情况下,基于流式输入进行稳定、在线的学习并避免灾难性遗忘,仍然是深度学习领域的一个复杂且重要的问题。在线持续学习为我们提供了机会去构建更加灵活、智能的模型,以应对不断变化的现实世界需求,推动算法落地于实际生活中。
[1] D. Wang, E. Shelhamer, S. Liu, B. Olshausen, and T. Darrell, “Tent: Fully Test-time Adaptation by Entropy Minimization.” arXiv, Mar. 18, 2021. doi: 10.48550/arXiv.2006.10726.
[2] J. Hong, L. Lyu, J. Zhou, and M. Spranger, “MECTA: Memory-Economic Continual Test-Time Model Adaptation,” presented at the The Eleventh International Conference on Learning Representations, Feb. 2023. Accessed: May 06, 2023. [Online]. Available: https://openreview.net/forum?id=N92hjSf5NNh
[3] A. Khurana, S. Paul, P. Rai, S. Biswas, and G. Aggarwal, “SITA: Single Image Test-time Adaptation.” arXiv, Sep. 07, 2022. doi: 10.48550/arXiv.2112.02355 .
[4] T. Gong, J. Jeong, T. Kim, Y. Kim, J. Shin, and S.-J. Lee, “NOTE: Robust Continual Test-time Adaptation Against Temporal Correlation.” arXiv, Jan. 11, 2023. doi: 10.48550/arXiv.2208.05117.
[5] S. Niu et al., “Towards Stable Test-Time Adaptation in Dynamic Wild World.” arXiv, Feb. 23, 2023. doi: 10.48550/arXiv.2302.12400.
[6] Y. Wu and K. He, “Group Normalization,” presented at the Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 3–19. Accessed: Jun. 02, 2023. [Online]. Available: https://openaccess.thecvf.com/content_ECCV_2018/html/Yuxin_Wu_Group_Normalization_ECCV_2018_paper.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}