语音是人与人之间交流最自然的方式,对语音信号的采样和处理是通信技术的研究热点。随着音频设备采样率的提升,以及语音信号在变换域的能量集中特性,使得语音信号的压缩不仅需要而且可行。传统的语音压缩多是有损压缩,它借助心理声学模型,将人耳不敏感的成分直接丢弃,而不引起听觉上的改变。然而对于一些后续的处理带来了不便,比如语音识别需要提取语音的全部参数来训练模型,有损压缩会极大地影响识别准确率。当然如果识别发生在临场,比如机器人通过麦克风采集语音并识别,这种情况可能不需要压缩。然而如果需要传递至远方并由机器来识别,那么压缩和高精度的重建同时需要。压缩感知技术正是进行压缩和精确重建所需要的技术。具体到语音信号,它是由声带振动以及空气湍流作用于声道而产生,一般情况下这些作用会延续一段时间,这可以用短时平稳性来解释,另一方面也说明相邻的帧存在一定的相关性。分帧是语音信号处理的通用做法。一般认为一帧时间段语音是平稳的,其频谱是稳定的;而且相邻帧的频谱是缓慢变化的,这种渐变特性可以用马尔可夫链来建模,利用了这一信息可以使得重建的精度更高。

首先将分帧后的语音分别做频域变换,每一帧的频域系数形成系数矩阵的一列,所有帧的系数形成一个矩阵。我们假设帧与帧的系数存在相关性,就像上图所示:我们用马尔可夫链表示这种相关性。
为了将数据进行压缩,我们对每一帧系数乘以一个随机高斯矩阵,这个矩阵行数大大少于列数,所以乘以这样一个矩阵实现了数据的压缩,乘积称为测量向量。
我们用Turbo消息传递的模型来重建语音。这个模型可以用下图表示:
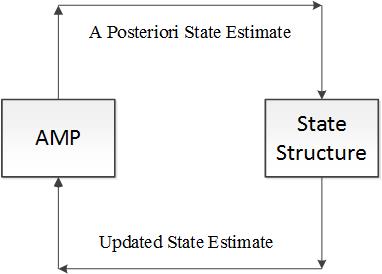
我们用AMP算法从各帧测量向量中估计原始系数,这个系数是一种后验估值;然后我们在后验估值形成的系数矩阵上进行消息传递,这里假设不同帧的同一个频率点形成了一个马尔可夫链,沿着马尔可夫链执行前-后向置信传播算法,如此我们利用了帧间相关性;消息传递完,我们把更新后的系数传递回执行AMP算法的部分,过程如上图所示。可见,这是一个迭代更新的过程,类似于数字通信中的Turbo均衡。
下面的表格显示的是利用了帧间相关性的算法(Proposed)和传统的正交匹配追踪(OMP)算法在一段25秒长、采样率为16k的语音上的重建精度,数据显示的是在不同帧长下的重建精度(SNR),压缩比统一设置成1/4。
|
帧长 |
480 |
560 |
640 |
720 |
800 |
|
Proposed |
12.7142 |
12.5286 |
12.3626 |
12.2985 |
12.1724 |
|
OMP |
10.5963 |
10.4729 |
10.4476 |
10.4174 |
10.5005 |
可以看出,基于帧间相关的算法对于帧长较为敏感,帧长较短的时候相邻帧的相关性大,利用马尔可夫链建模后得到的信噪比更高;而正交匹配追踪不受帧长的影响,它只是寻找帧内幅度最大的频率成分。整体上来看,利用帧间相关信息的算法比没有利用结构信息的算法的信噪比明显要好。


{kind=link}
{kind=link}
{kind=link}
{kind=link}