背景
避障是机器人导航必不可少的功能之一。避障算法可分为基于地图(map-based)和反映式(reactive)两种,基于地图的算法由于需要实时更新障碍物地图,往往计算量较大,而且对动态障碍物的躲避效果相对较差;而反映式的算法直接从传感器获得的信息分析计算最后的机器人控制量,计算量一般小于基于地图的算法。
近年来一些学者在使用深度强化学习去解决一些具有马尔可夫性的问题上获得了一定的成功,避障领域也开始引入深度强化学习的方法去构建避障的模型。与传统方法相比,强化学习的方法完全由模型自己学习避障的控制,如果在新场景下发生碰撞,可以利用碰撞的经验进行学习,有一定的自我改进和环境适应能力。
算法
我们从基本的强化学习模型DDPG(Deep Deterministic Policy Gradient)开始构建自己的模型。模型的输入是维度压缩的单线激光、目的地坐标和小车的速度,输出小车的控制量(线速度和角速度)。
首先,我们引入了一个辅助训练机制保证训练速度。辅助训练机制就是设计一个简单的控制器(一般这个控制器可以直接根据终点坐标计算小车控制量,即如果没有障碍物,它可以直接控制小车到达目的地),利用DDPG的critic网络选择网络输出的行为和简单控制器的输出行为中Q值较高的行为,增加训练过程中好行为的出现,进而提高训练效果。
然后,我们提出镜像经验回放机制提高训练效果。考虑到单线激光、目的地、速度、小车控制量等信息都是左右对称的,我们可以利用这个特性把训练的经验镜像复制,提高经验获得效率。
最后,我们添加了一个子目标生成模块降低避障的难度。如果目的地隐藏在一个大型障碍物后,可能模型会陷入某些局部最低点而不移动,我们用一个简化传统避障算法给出一个可视范围内的目标点替代原目的地,可有效降低陷入局部最低点的情况,提高避障成功率。
我们的模型结构如图1所示。其中,在使用时我们只需要把输入信息依次经过subgoal generator和actor网络即可输出小车的控制。
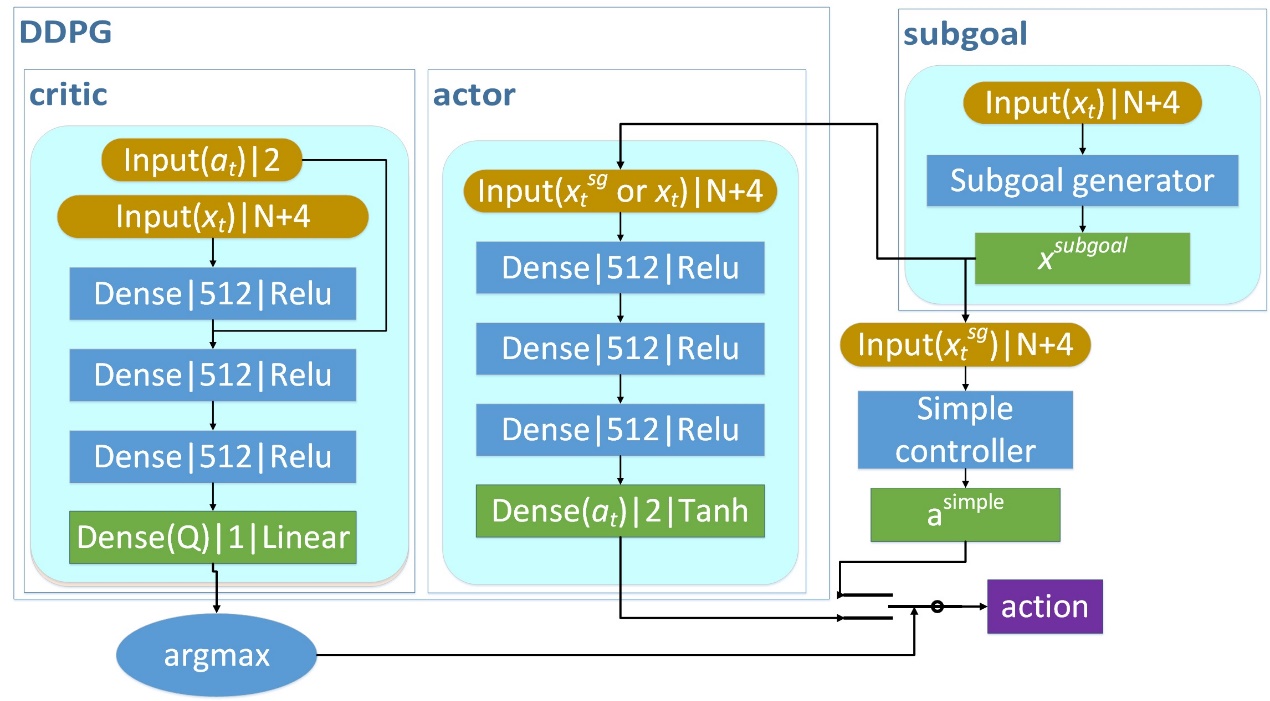
图1 模型框图
实验
我们首先在gazebo仿真环境里对模型进行了训练和测试,场景如图2,左边为训练场景,右边为测试场景。测试场景的障碍物比训练场景多,而且形状更大。

图2 仿真场景
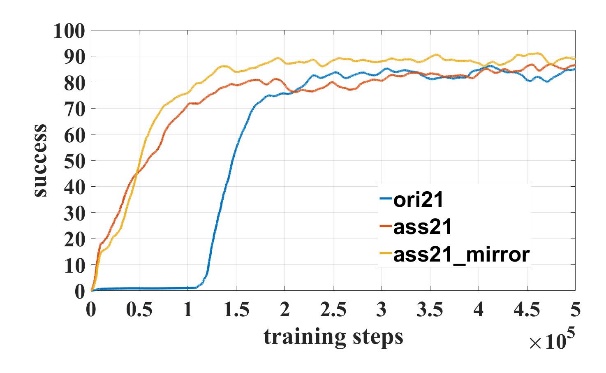
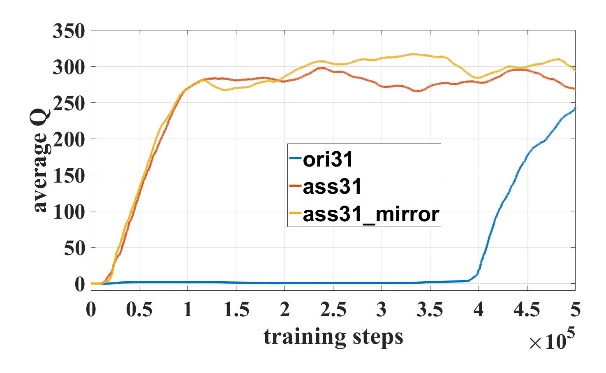
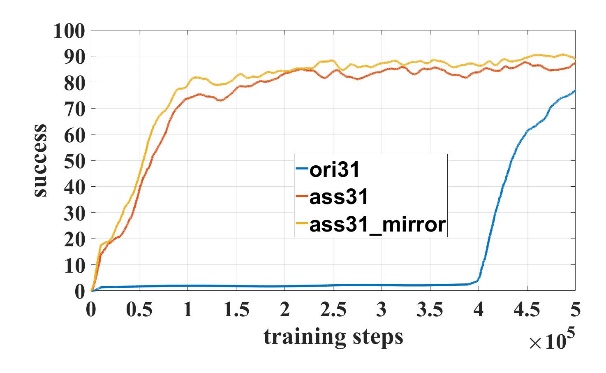
我们对模型进行了50万步的训练。在训练过程中成功率和Q值曲线如图3所示,其中模型名字数字表示输入激光维度,”ori”表示原始DDPG模型,”ass”表示使用了辅助训练机制,”mirror”表示使用了镜像经验回放。对比21维和31维训练曲线可知,输入维度越高,辅助训练机制越可以加快训练速度。
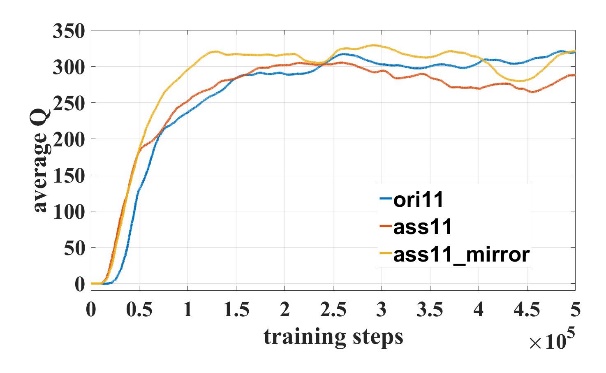
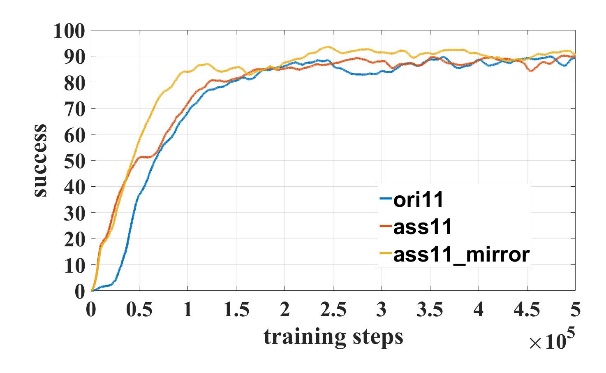
(a) (b)
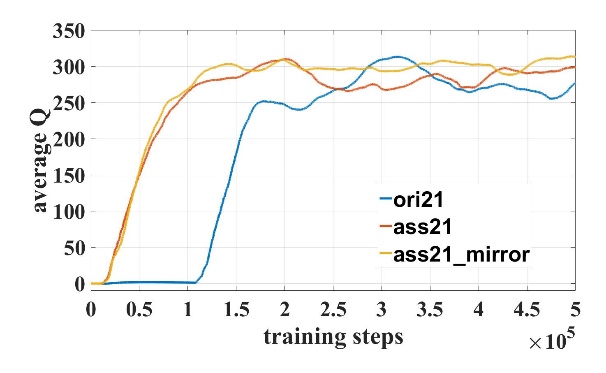
(c) (d)
(e) (f)
图3 训练曲线
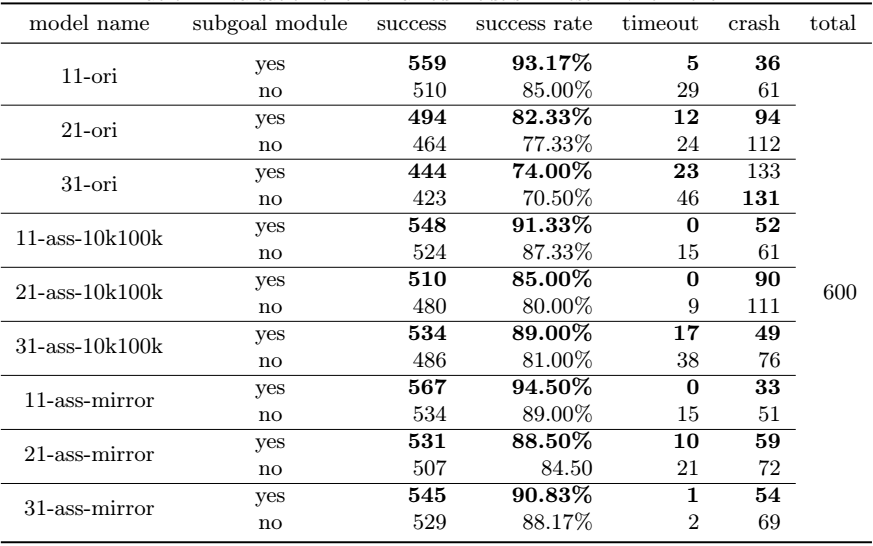
我们在仿真测试场景里随机生成600个起点终点,测试不同模型的避障成功率,测试结果如表1,表中subgoal module一列表示是否有子目标生成模块,模型名字第一个数字表示输入激光维度,”ori”表示原始DDPG模型,”ass”表示使用了辅助训练机制,”mirror”表示使用了镜像经验回放。对比表格可知:所有有子目标生成模块的模型避障成功率都比没有子目标生成模块的模型高;有镜像经验回放训练机制的的模型避障成功率比没有使用镜像经验回放的模型高。实验结果证明我们的算法对模型避障成功率有一定的提高。
表1 仿真环境不同模型随机起/终点避障测试结果
最后,我们在真实场景里把模型放入一个SLAM导航系统里进行测试,实验轨迹如图4,图中红色线条表示SLAM记录的轨迹,蓝色线条表示SLAM丢失的起始和结束位置,绿色点表示终点,图中还有一些导航过程的快照。我们的模型成功在复杂场景里进行导航避障任务,并且在slam丢失的情况下仍进行了可靠的导航直到SLAM重新找回定位。实验视频可在这个网址观看:https://www.youtube.com/playlist?list=PLzNPkB9TFmwbscH1WmiHLXNF7p_w8Cq1o。
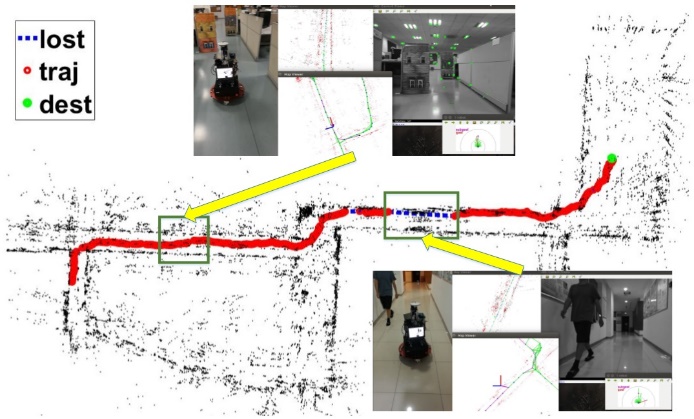
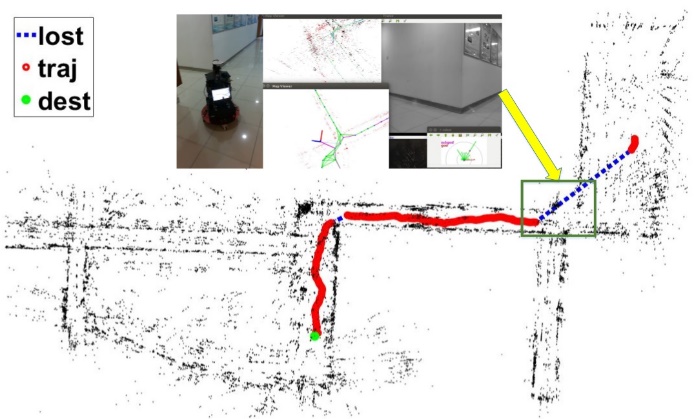
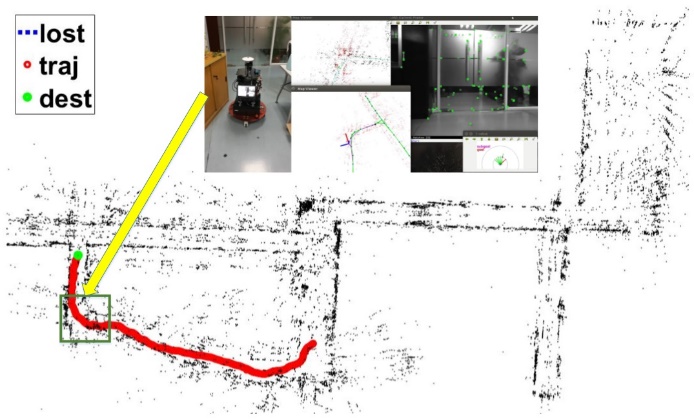
图4 真实场景测试



{kind=link}
{kind=link}
{kind=link}