特定人语音增强技术研究
我们利用增强型最小控制递归平均(IMCR)的噪声估计和面向决策的先验信噪比估计,提出基于统计模型的语音增强算法。在训练阶段,获得通用的梅尔倒谱系数的混合高斯模型。在语音增强阶段,利用当前帧的噪声功率谱和可调权重因子来调节IMCR噪声估计的最小跟踪进程。另外,基于统一混合高斯模型,一些重要的常量参数用频率变化参数来代替。例如这些参数:在决策方向先验信噪比估计中的权重参数,在IMCR的修正最小跟踪进程的调节权重因子。我们在各种稳态和非稳态噪声环境下评估可该语音增强算法的表现。从实验结果看,该算法比传统语音增强算法更适合作为语音处理系统的预处理方案。
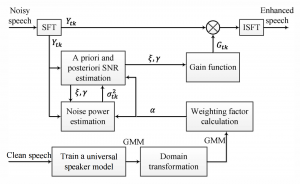
图1 基于同一说话人模型的语音增强算法的总框图
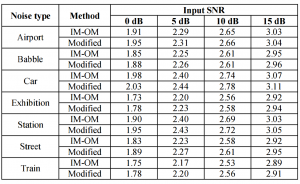
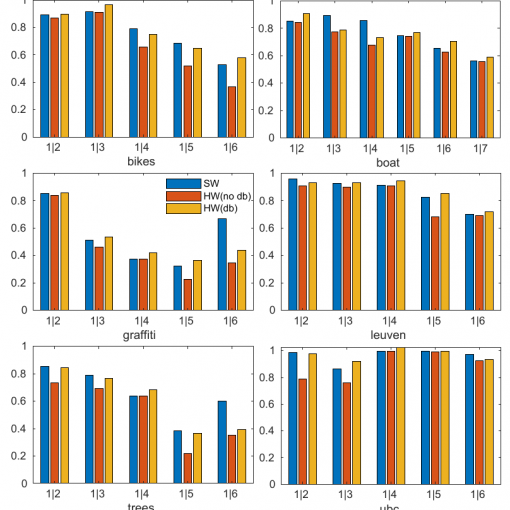
表1 传统的和增强方法的感知语音质量评估(PESQ)结果
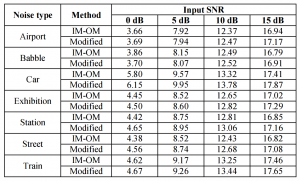
表2 总信噪比结果比较
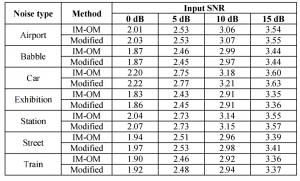
表3 总体水平的组合测量(Covl)结果比较
你可能也喜欢
架构特点 1)整体为串并行混合架构,3个尺度 […]
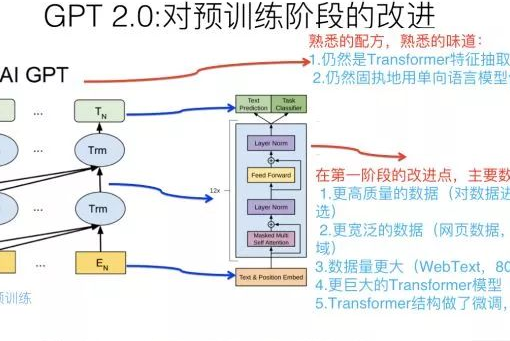
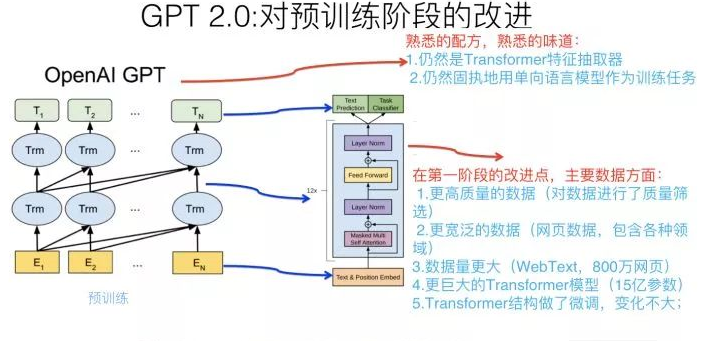
在谈GPT 2.0之前,先回顾下GPT 1. […]
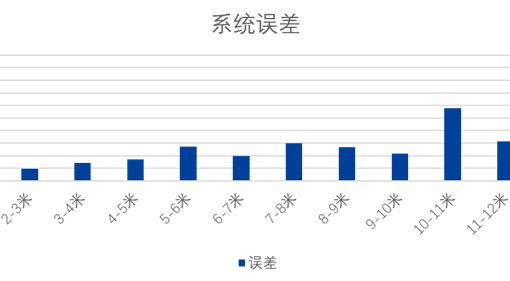
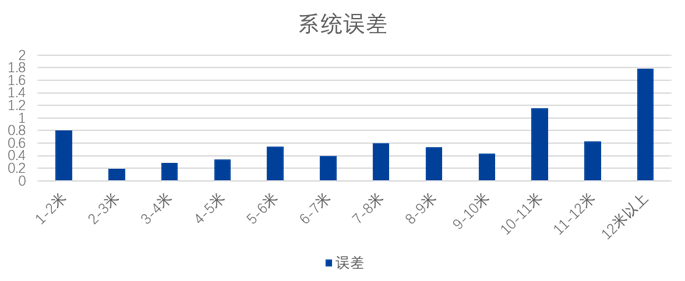
车载行人定位技术是智能驾驶中重要的技术,该技 […]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
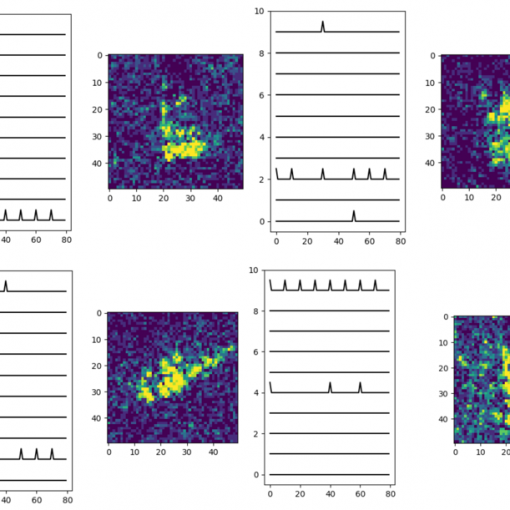
针对类脑计算片上海量脉冲神经元高效可靠的通信 […]