在谈GPT 2.0之前,先回顾下GPT 1.0,过程参考下图

简述如下:GPT 1.0采取预训练+FineTuning两个阶段,它采取Transformer作为特征抽取器。预训练阶段采用“单向语言模型”作为训练任务,把语言知识编码到Transformer里。
第二阶段,在第一阶段训练好的模型基础上,通过Finetuning来做具体的NLP任务。GPT 1.0本身效果就很好,不过之前说过,因为不会PR,所以默默无闻,直到Bert爆红后,才被人偶尔提起。从大框架上来说,Bert基本就是GPT 1.0的结构,除了预训练阶段采取的是“双向语言模型”之外,它们并没什么本质差异,其它的技术差异都是细枝末节,不影响大局,基本可忽略。
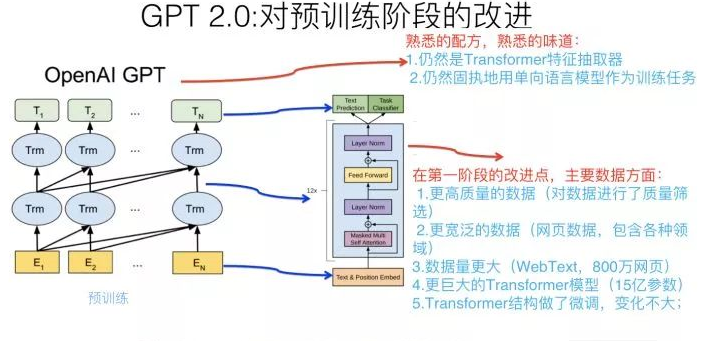
它的大框架其实还是GPT 1.0的框架,但是把第二阶段的Finetuning做有监督地下游NLP任务,换成了无监督地做下游任务,为啥这么做?后面会讲。我相信如果你理解GPT 1.0或者Bert,那么是非常容易理解GPT 2.0的创新点在哪里的。那么它最大的改进在哪里?
本质上,GPT2.0选择了这么一条路来强化Bert或者是强化GPT 1.0的第一个预训练阶段:就是说首先把Transformer模型参数扩容,常规的Transformer Big包含24个叠加的Block,就是说这个楼层有24层高,GPT 2.0大干快上,加班加点,把楼层连夜盖到了48层,高了一倍,参数规模15亿,这个还是很壮观的,目前貌似还没有看到过Transformer楼层有这么高的模型。
那么,为什么要扩容呢?这个只是手段,不是目的。真正的目的是:GPT 2.0准备用更多的训练数据来做预训练,更大的模型,更多的参数,意味着更高的模型容量,所以先扩容,免得Transformer楼层不够多的房间(模型容量)容纳不下过多的住户(就是NLP知识)。水库扩容之后,我们就可以开闸放水了。
本质上GPT 2.0主要做的是:找更大数量的无监督训练数据,这个其实好办,反正是无监督的,网上有的是,估计未来有一天我写的这篇文章也能住进GPT 2.0的Transformer客房里。所以,GPT2.0找了800万互联网网页作为语言模型的训练数据,它们被称为WebText。当然,光量大还不够,互联网网页还有个好处,覆盖的主题范围非常广,800万网页,主题估计五花八门,你能想到的内容,除了国家禁止传播的黄赌毒,估计在里面都能找到。
这带来另外一个好处:这样训练出来的语言模型,通用性好,覆盖几乎任何领域的内容,这意味着它可以用于任意领域的下游任务,有点像图像领域的Imagenet的意思。GPT 2.0论文其实更强调训练数据的通用性强这点。当然,除了量大通用性强外,数据质量也很重要,高质量的数据必然包含更好的语言及人类知识,所以GPT 2.0还做了数据质量筛选,过滤出高质量的网页内容来。
之后,GPT 2.0用这些网页做“单向语言模型”,我这里强调下,仍然是类似GPT 1.0的单向语言模型,而不是Bert的双向语言模型任务,后面我会单独讲下对这个事情的看法。这样GPT就可以训练出一个更好的预训练模型了,尽管GPT 2.0没有像Bert或者1.0版本一样,拿这个第一阶段的预训练模型有监督地去做第二阶段的Finetuning任务,而是选择了无监督地去做下游任务,尽管这看着和Bert差异很大,其实这点并不重要,甚至你都可以忽略掉这个过程(当然,最吸引眼球的是第二个过程),要记住对于GPT 2.0来说最重要的其实是第一个阶段。
其实,如果你不是非常专业的前沿NLP研究者的话,了解GPT 2.0,这就足够了,这即使不是GPT 2.0的百分之百,也有它的百分之80了。至于它提到的对Transformer结构的微调,以及BPE输入方式,我相信都是不太关键的改动,应该不影响大局。


{kind=link}
{kind=link}
{kind=link}