近期,实验室在人脸活体检测方面的研究成果被信息安全领域顶刊IEEE Transactions on Information Forensics & Security(TIFS)录用发表(CCF A类期刊,中科院1区,影响因子:7.231)[1]。
受人类判断样本是否为真实人脸是先全局概览再仔细观察的方式启发,许多相关研究已经表明基于图像patch利用CNN结合局部特征和全局特征的方法是有效的。然而CNN逐步聚合局部信息的方式限制了其无法有效捕捉长距离依赖关系。最近,Vision Transformer等方法可以捕捉长距离依赖,但受限于弱归纳偏置,其需要大规模的数据用于预训练。此外,其通过图像全尺寸点积计算注意力分数矩阵,计算量较大。
通过分析对比MLP、CNN、RNN、Transformer在捕捉长距离依赖关系上的归纳偏置特性,提出了结合卷积操作提取局部特征与MLP获取长距离依赖的Conv-MLP网络结构,利用卷积提取每个patch的局部特征,通过MLP对所有patch进行交互并融合patch间的特征,既可以提取局部信息又能捕获长距离依赖关系。Conv-MLP解决了CNN和RNN的局部归纳偏置限制和Transformer、MLP-Mixer由于数据饥饿导致需要大规模数据预训练的问题。与ViT相比,Conv-MLP合理利用卷积运算,其归纳偏置比ViT强,不需要大规模的预训练。Conv-MLP利用长、短距离依赖关系更好地提取图像特征,应用于活体检测任务并取得了出色表现。
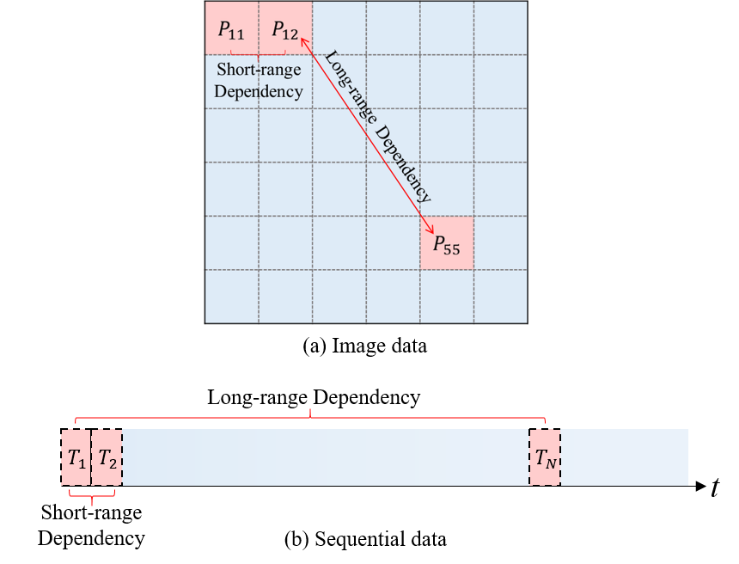
图1 长、短距离依赖关系示意图
下表对比了深度学习不同模块的相关归纳偏置:
Table I
Various relational inductive biases in deep learning components.
|
Component |
Entities |
Relations |
Inductive Bias |
|
MLP |
Units |
All-to-All |
Weak |
|
CNN |
Grid elements |
Local |
Locality |
|
RNN |
Time steps |
Sequential |
Sequentiality |
|
Vision Transformer |
Patch embeddings |
Full-sized |
Weak |
|
Conv-MLP |
Patch embeddings |
Cross-Patches |
Medium |
- CNN: 卷积核(convolutional kernels)专为捕获局部短距离时空信息而设计,具有平移不变性,其作用范围是感受野网格(grid)内元素,无法捕捉超出感受野范围的信息。随着网络加深,多个卷积核叠加可以自然扩展感受野,但聚合局部信息的方式对于长距离依赖的捕获仍是受限的。
- RNN: 循环操作(recurrent operations)专为序列输入捕获长距离依赖而设计。RNN以一个序列作为输入,并按时间步(time step)更新状态,在时间序列上权重共享,具有时间不变性。RNN根据前一步隐状态和当前输入更新状态,因此也不可避免地带来了局部归纳偏置。
- Self-Attention: 自注意力层以全连接结构一次性与所有位置建立连接,因此归纳偏置较弱,需要大规模数据预训练。
- Conv-MLP: 我们提出的Conv-MLP同样将图像切割成多个patch,利用MLP对所有patch对应位置像素进行交互,打破了CNN局部归纳偏置的限制。通过固定次数操作,每个像素都可以与图像上的任意位置建立联系,从而有效捕获长距离依赖关系。
Conv-MLP block由单一patch局部卷积、跨patch交互MLP和分类模块三部分组成,如图2所示。
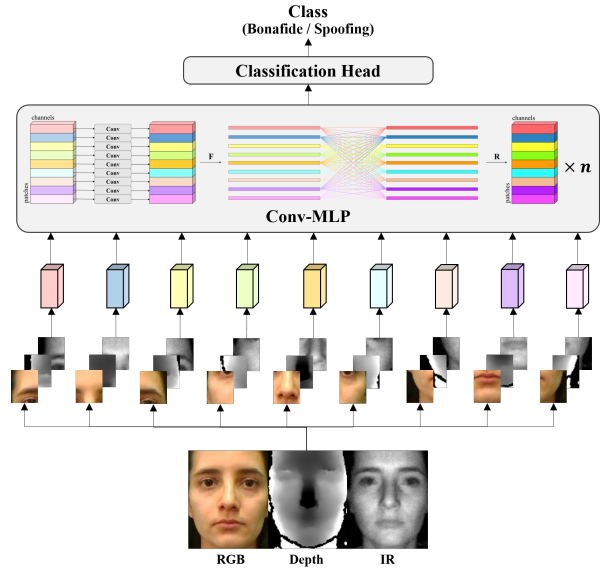
图2 Conv-MLP网络结构图
其中,跨patch交互MLP的结构如图3所示。不同的颜色代表不同位置的图像patch。首先,卷积运算从邻域像素中提取局部特征,并独立捕获每个patch的近距离依赖关系。然后,MLP实现patch之间的交互,从而捕获远距离依赖关系。我们将patch的数量记作N,权重矩阵尺寸为的MLP可被视为N个维度为N的卷积,实现N个patch间的特征交互。
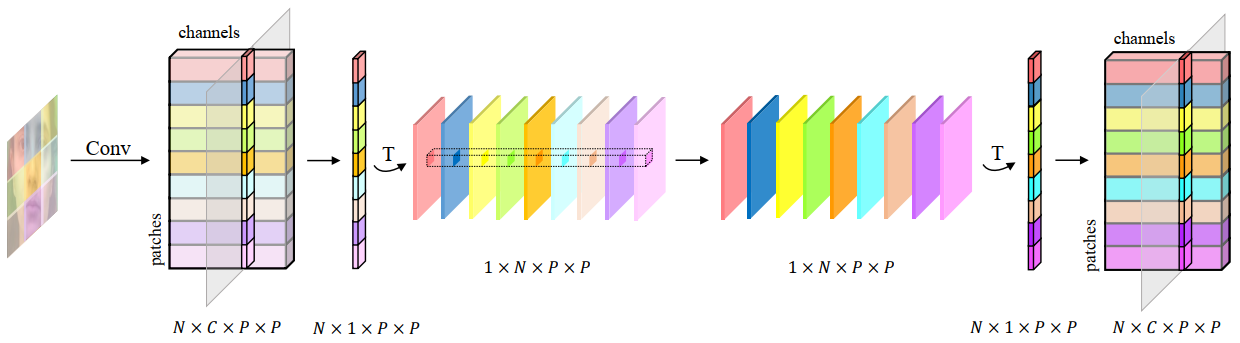
图3 跨patch全局交互示意图。N为patch个数,C为特征维度,为patch尺寸。
我们在多个活体检测数据集上将Conv-MLP与SOTA结果对比,验证其在单一模态和多模态数据下的有效性,包括4个多模态数据集:WMCA、HQ-WMCA、CeFA、CASIA-SURF;2个RGB数据集:OULU-NPU和SiW。实验结果表明,Conv-MLP在单一模态和多模态数据集下与SOTA结果相比,均取得了具有竞争性的表现。
此处以WMCA数据集上的实验结果为例展示,以平均分类错误率(ACER)作为评价指标,如表2所示。
Table II
Comparison of Accuracy among Different Methods under LOO Protocol of WMCA Dataset.
|
Method |
Fake head |
Glasses |
Paper mask |
Rigid mask |
Flexible mask |
|
Replay |
ACER |
|
MCCNN |
1.9 |
50.0 |
4.8 |
18.3 |
22.8 |
30.0 |
31.4 |
22.74±15.33 |
|
DenseNet |
0.4 |
45.5 |
6.9 |
12.7 |
28.2 |
– |
32.4 |
21.02±15.67 |
|
ResNet |
2.5 |
48.3 |
18.2 |
15.4 |
33.2 |
3.5 |
15.8 |
19.56±16.09 |
|
MH-BCE |
3.1 |
37.6 |
1.0 |
2.2 |
33.7 |
1.7 |
1.0 |
11.47±15.34 |
|
MA-Net |
2.1 |
36.7 |
0.9 |
9.8 |
25.3 |
0.3 |
3.2 |
11.18±13.22 |
|
PixBiS |
0.7 |
16.0 |
0.2 |
3.4 |
49.7 |
0.1 |
3.7 |
10.54±16.79 |
|
MLP-Mixer-B/32 |
5.8 |
35.8 |
1.8 |
2.4 |
19.9 |
3.1 |
2.0 |
10.11±12.05 |
|
FaceBag |
1.2 |
13.7 |
2.3 |
2.6 |
31.6 |
4.5 |
8.5 |
9.20±9.99 |
|
CDCN |
2.5 |
19.8 |
4.5 |
9.7 |
7.9 |
2.8 |
8.6 |
7.99±5.51 |
|
MH-CMFL |
2.5 |
33.5 |
1.8 |
1.7 |
12.4 |
0.7 |
1.0 |
7.66±11.21 |
|
ViTFAS |
2.7 |
15.9 |
2.3 |
9.5 |
2.6 |
– |
12.4 |
7.56±5.36 |
|
Ours (BCE) |
0.5 |
33.7 |
1.0 |
3.8 |
13.8 |
0.5 |
1.2 |
7.78±11.45 |
|
Ours (Moat) |
0.2 |
32.5 |
0.9 |
2.3 |
12.6 |
0.1 |
0.8 |
7.05±11.16 |
在基于CNN的方法中,CDCN取得了最好的平均分类错误率(ACER:7.99%)。此外,我们观察到,损失函数的改进使得多头卷积模型MH-CMFL相较MH-BCE的性能显著改善,ACER降低近4%。基于ViT的方法实现了SOTA结果(ACER:7.56%),但它是在ImageNet上进行预训练的。
基于BCE损失训练的Conv-MLP取得了ACER为7.78%,优于CDCN,与基于ViT的方法(ViTFAS)相媲美。实验结果表明,Conv-MLP捕获长距离依赖关系的能力确实提高了分类性能。此外,在以moat loss损失训练条件下,Conv-MLP取得了最佳的ACER(7.05%)。与ViTFAS相比,Conv-MLP未经任何预训练,并且ACER降低了0.5%。实验结果表明,moat loss进一步有效提高了模型应对未见过攻击的泛化能力。
此外,在其余5个RGB或多模态数据集上的结果也体现了Conv-MLP的有效性。更多实验结果请见论文内容。
小结
本项工作设计了一套简单且有效的特征提取网络结构,结合局部卷积与全局MLP,打破了CNN固有的局部归纳偏置,实现了长距离依赖关系的捕捉能力,更好提取特征。通过合理利用CNN使得Conv-MLP具有适中的归纳偏置,不需要大规模数据用作预训练。此外,设计moat loss挖掘困难样本、扩大类间差异,提高了模型对未见过假脸攻击的泛化能力。
目前本项工作《Conv-MLP: A Convolution and MLP Mixed Model for Multi-Modal Face Anti-Spoofing》已被信息安全领域顶刊IEEE Transactions on Information Forensics & Security录用发表(CCF A类期刊,影响因子:7.231)。
[1] W. Wang, F. Wen, H. Zheng, R. Ying and P. Liu, “Conv-MLP: A Convolution and MLP Mixed Model for Multimodal Face Anti-Spoofing,” in IEEE Transactions on Information Forensics and Security, vol. 17, pp. 2284-2297, 2022

{kind=link}
{kind=link}