We propose a statistical model-based speech enhancement algorithm using an improved minima controlled recursive averaging (IMCR) noise estimation and a decision-directed (DD) priori SNR estimation. In the training stage, the Gaussian mixture model (GMM) of the Mel-frequency cepstral coefficients (MFCCs) of universal speaker is obtained. In speech enhancement stage, minima tracking process of IMCR noise estimation is adjusted with the noisy power spectrum of current frame and an adjustment weighting factor. In addition, based on the universal GMM, some significant constant parameters are replaced by frequency-varying parameters, such as the weighting parameter in the DD priori SNR estimation and the adjustment weighting factor in the modified minima tracking process of IMCR. The performance of proposed speech enhancement is evaluated by objective tests under various stationary and non-stationary noise environments. From experimental results, compared to the conventional approaches, the proposed scheme performs better and is suitable for being used as the pre-processing of speech processing systems.
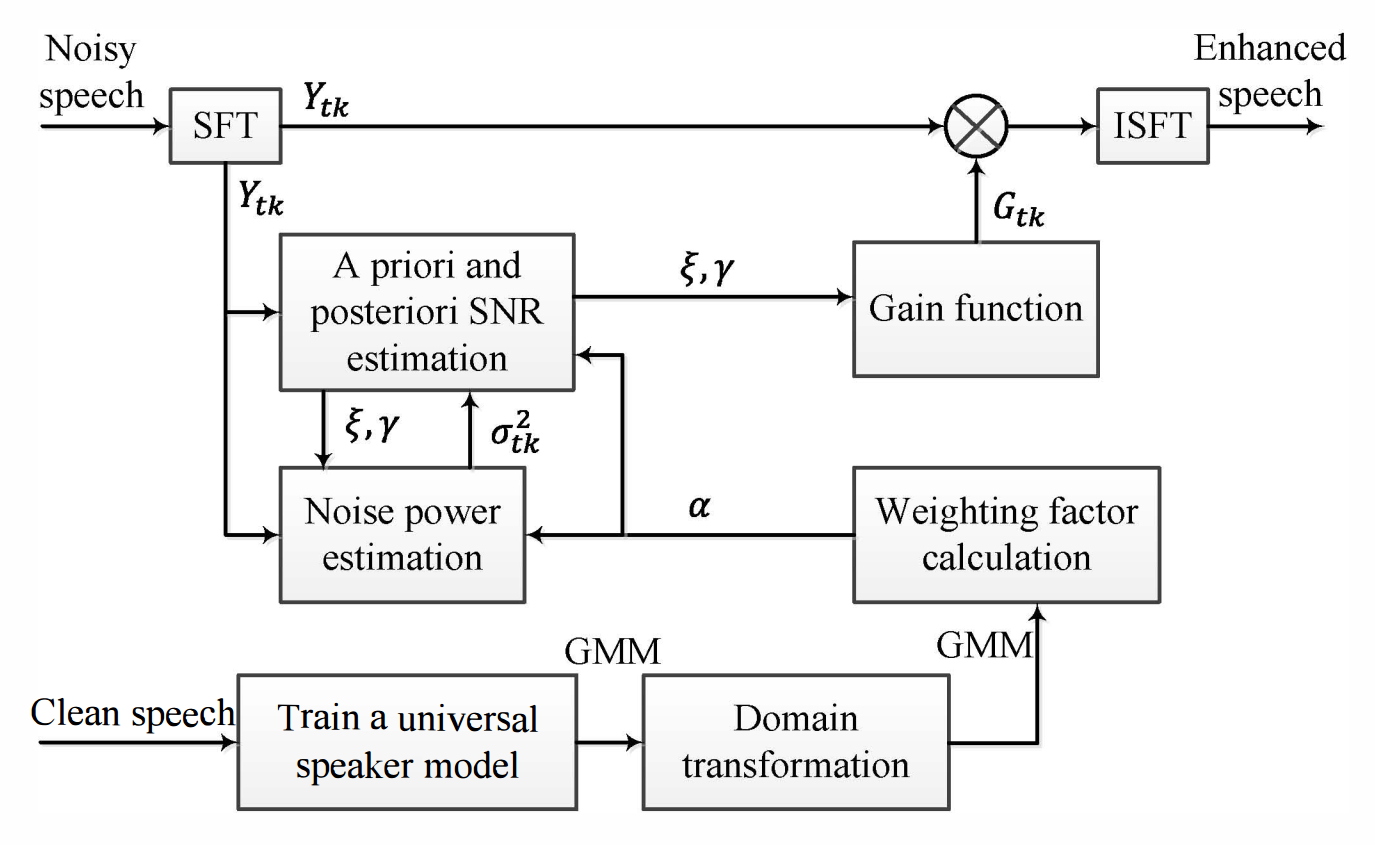
Figure 1. Overall block diagram of speech enhancement algorithm based on a universal speaker model
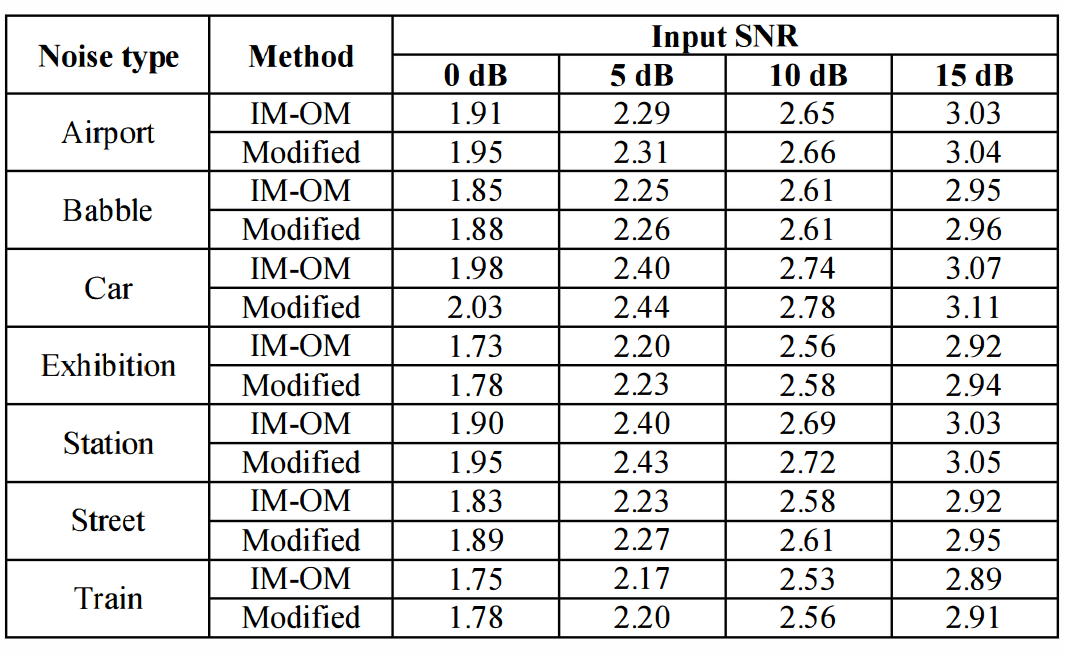
Table 1. PESQ results obtained from the conventional and modified methods
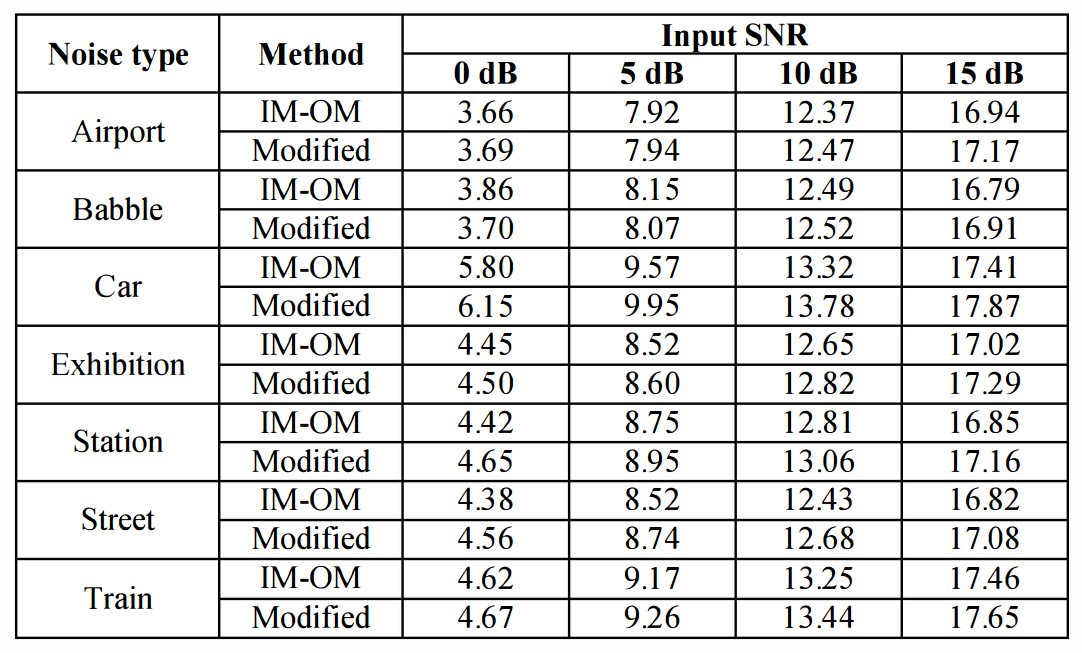
Table 2. Global SNR results Comparison
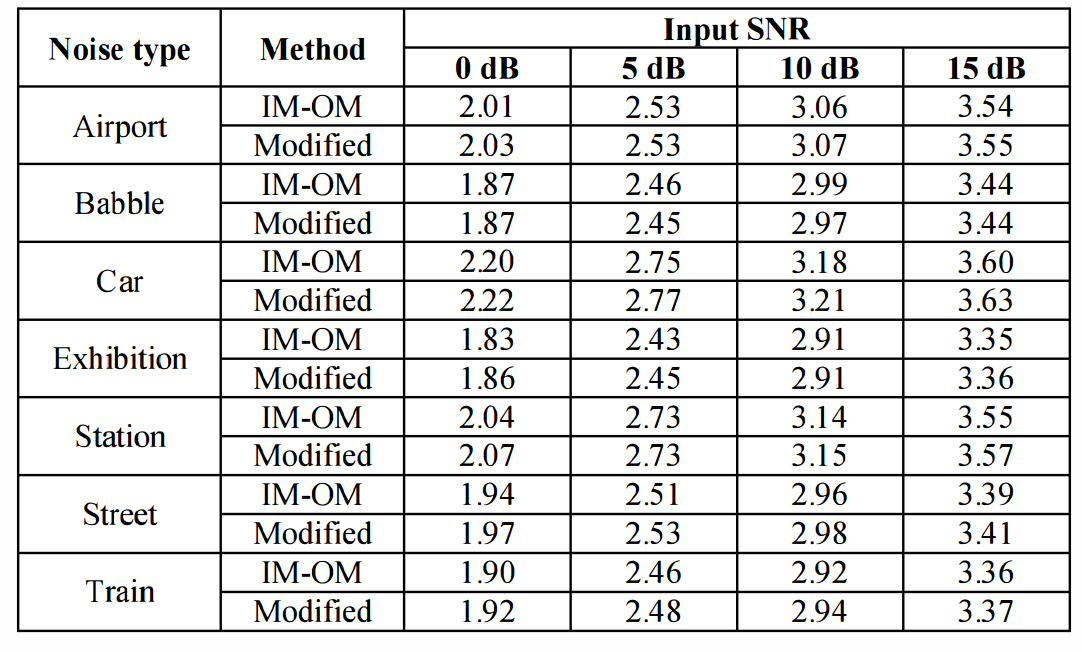
Table 3. Composite measure Covl results comparison