摘要:曾经我们只有亲眼看到的才是3维世界,图片、视频展示给我们的只有平面信息。什么时候才能像科幻大片中描述的未来世界一样呢,全息投影,AR眼镜成为标配,现在这些场景已经不再是遥不可及,ToF相机、激光等都带给了我们前所未有的3维信息,如何应用与处理3D数据就成为了关键的一步。
随着信息时代的不断发展,数字化世界在逐步的完善,同时3维激光和ToF(Time-of-Flight)深度摄像机的发展,使得3D表现形式及相关应用逐渐走入大家的视线,AI+3D成为世人瞩目的领域。在这过程中,3D技术是推进工业化与信息化融合的发动机,同时也是各个行业产业的新的战略性的工具和技术。iPhone X 搭载深度摄像机进行面容识别已经走进了我们的生活,今天我们首先就来看看如何处理3D数据,以此奏响我们3D篇章的序曲。
首先,我们来了解一下3D表现形式主要有哪些,在十几年前,最常见的是用多张不同角度的图片(multi-view images)来表现某物体的三维形态,




上述几种数据在广泛意义上都属于3D数据[1],本文接下来主要介绍近几年最常用的深度图和点云的处理方式方法。
深度图(Depth Map)
深度图(Depth Map)一般是由深度相机获得的包含与视点的场景对象的表面的距离有关的信息的图像。Depth Map 类似于灰度图像,只是它的每个像素值是传感器距离物体的实际距离。深度图的处理与传统的图像处理有很多相似之处,例如去噪,压缩,分割,提取特征等操作。接下来简单介绍深度图处理的具体需求和典型算法。
深度图去噪
深度图的去噪与传统RGB去噪有相似的要求,尽量保持细节的情况下使平面更光滑,去除传感器(深度相机)带来的噪声。


 KinectFusion[2]当中对深度图做的预处理就是通过双边滤波去噪。双边滤波的特点主要为对于边缘(细节)保持较好,计算速度在普通的CPU上都可以达到实时处理。另外还有结合RGB对深度图进行处理的算法,在追求高精度高质量的去噪的时候,可以利用RGB进行引导,先检测RGB边缘等再进行多边滤波,但是这种高精度的处理在实时性方面表现较差。
KinectFusion[2]当中对深度图做的预处理就是通过双边滤波去噪。双边滤波的特点主要为对于边缘(细节)保持较好,计算速度在普通的CPU上都可以达到实时处理。另外还有结合RGB对深度图进行处理的算法,在追求高精度高质量的去噪的时候,可以利用RGB进行引导,先检测RGB边缘等再进行多边滤波,但是这种高精度的处理在实时性方面表现较差。
原始深度图 带噪深度图 

 双边滤波结果
双边滤波结果
原始RGB图 带噪RGB图 结合RGB的低秩恢复结果
除去与传统图像相似的去噪处理,通过深度相机获得的深度图还有很多无效值,例如下图中的红圈中圈出来的白色空洞,

一般情况下,反光表面和黑色吸光表面会产生较多的空洞,通过利用周围值进行补全(与形态学滤波先膨胀后腐蚀类似)可以实现简单的补空洞,该方法在普通的CPU上就可以达到实时。由于深度图用矩阵表示都是低秩的,所以也可以用矩阵补全[3]的方法进行恢复,该方法相对而言更加精确,另外先低秩表示再恢复也在一定程度上实现了去噪,但是目前矩阵补全的算法在CPU上无法实时处理图片。
深度图压缩
未来的深度信息会像如今视频图像信息一样应用广泛,所以传输成为很关键的一部分,随之压缩也就成为了深度图信息处理的重要一步。
传统的RGB图像压缩主要根据人眼对于高频信息不敏感的特性,利用JPEG压缩方法可以忽略高频信息减少信息含量从而实现压缩,压缩之后仍能够保留符合人眼观察重要信息,同时对于三通道中亮度保留了更多细节。
但是深度图不是给人类直接观察的,而是存储信息,所以不应该以人眼的主观评判方式来进行深度图压缩,深度图仍需要保存高频部分的边缘距离信息,除去峰值信噪比之外最直观的评判依据是转换为点云仍能够正确表现原来物体空间结构。现行的压缩方式有通过将深度图16bit的信息编码为3个8bit的类似于YCbCr的信息,利用JPEG等适用于彩色图像的压缩算法处理数据,然后再解码出16bit深度信息。

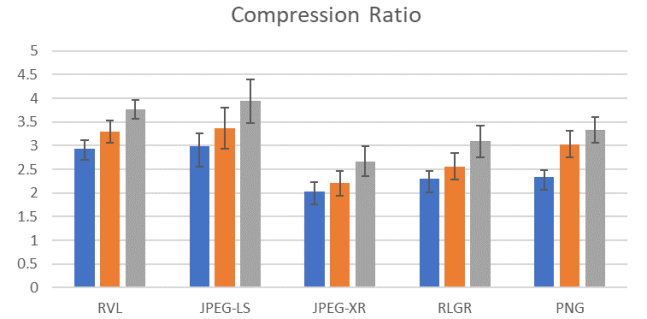
也有Kinect研究院[4]提出的直接适用于16bit深度图的RVL无损编码压缩算法,压缩率与其他算法对比如下。
深度图分割
传统的分割方法可以根据深度图的距离的梯度进行分割,在机器学习、神经网络发展迅速的今天,利用神经网络的语义分割更为精确和有意义。
利用SUNRGB-D网络[5]实现的RGB-D语义分割如下所示。

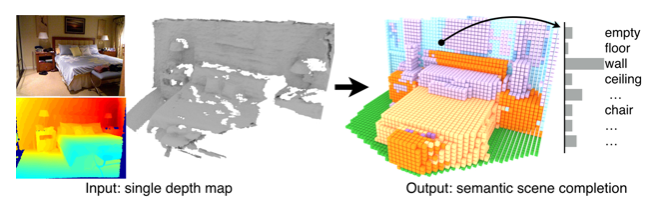
斯坦福大学[6]提出的针对单张深度图给出语义标签并给出完整的3D voxel表示的结果如下所示。
点云(Point Cloud)


 点云通常通过3D激光扫描得到或者通过深度图转换得到。
点云通常通过3D激光扫描得到或者通过深度图转换得到。SmartToF 3D相机模组 灰度图像 点云结果
针对点云这种形式的三维数据处理主要有点云滤波、分割、分类和重建等方面。
点云滤波
近些年,点云处理方面有著名的Point Cloud Library(PCL)[7]提供各种算法支持。四种常用的点云滤波算法为统计滤波(Statistical Outlier Removal)、半径滤波(Radius Outlier Removal)、直通滤波(Pass Through)、体素滤波(Voxel Grid)。统计滤波和半径滤波在处理点云边缘部分飞散点上效果突出;直通滤波可以去除不合理的和不需要的范围外的点;体素滤波可以很好地对点云进行降采样。
点云分割分类
点云分割与分类的各种算法主要为聚类算法,机器学习和神经网络等,2016年由斯坦福大学提出了Pointnet[8]并且取得的出色的效果之后,针对点云的神经网络结构设计便引起了众多科研人员的关注。Pointnet的具体分割、分类效果如下。
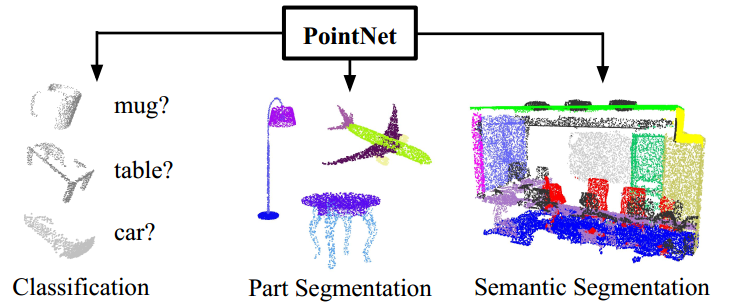
针对点云的学习主要有以下几个困难也是二维神经网络不能直接移植应用与三维数据处理的原因:点云的无序性,点云的大小不确定,同一个点云在不同坐标系下表示不同。解决上述几个问题之后,神经网络便能够在三维信息上取得较好的效果。Pointnet++和PointCNN等算法的效果在Pointnet的基础上又有了很大的提升。
点云重建
点云重建也是点云数据处理的重要一部分,通过迭代最近点(Iterative Closest Point, ICP)或者特征点的匹配,将TOF相机从不同角度获得的物体部分点云融合重建为一个完成的点云模型,主要算法有KinectFusion[1] 和PCL开源的Kinfu[9],两者都能得到基本与拍摄物体一致的三维点云模型。

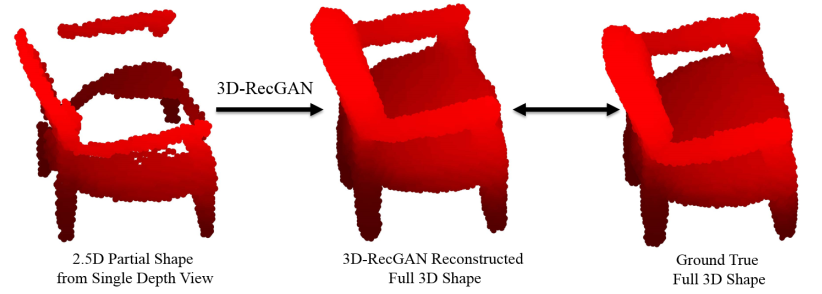
目前还有部分通过GAN网络[10]或者卷积网络利用单张RGB-D图片预测整个三维模型的算法,只不过该领域尚处于发展初期,所得结果并不完美,所以说还有很大发展空间。
总结
相比于传统的2D视觉,TOF相机[11]可以直接感知计算深度信息,对应双目获取距离信息来说,ToF计算复杂度很低,可以降低硬件的需求,提高实时性。相比于3D激光, ToF造价低,适应于当前科研与工业紧密结合的发展趋势。
在研究方面:
- 2D视觉有一定局限性:平面图形无法跃然纸上;不支持与形状相关的测量;物体运动只有X-Y方向;解决识别和分割问题时复杂场景难度较大
- 3D视觉有明显的优势:更立体的可视化,3D信息能够提供物体的空间点云;更丰富的数据采集,3D信息能辅助测量与形状相关的特征;更多维的运动方向,3D信息将物体的运动空间从X-Y方向扩展到X-Y-Z方向;能利用深度信息将物体从复杂背景分割
综上所述,深度相机获得3D信息的将会给我们的科研领域和工业领域开辟一个全新的时代,带来质的变化,在这浪潮中还需要更多的对三维领域感兴趣的你们和我们一起努力。
[1] Hao Su, 3D Deep Learning on Geometric Forms http://cseweb.ucsd.edu/~haosu/slides/NIPS16_3DDL.pdf
[2] R. A. Newcombe et al., “KinectFusion: Real-time dense surface mapping and tracking,” 2011 10th IEEE International Symposium on Mixed and Augmented Reality, Basel, 2011, pp. 127-136.
[3] S. Lu, X. Ren and F. Liu, “Depth Enhancement via Low-Rank Matrix Completion,” 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, 2014, pp. 3390-3397.
[4] D. Wilson, Andrew. (2017). Fast Lossless Depth Image Compression. 100-105. 10.1145/3132272.3134144.
[5] S. Song, S. P. Lichtenberg and J. Xiao, “SUN RGB-D: A RGB-D scene understanding benchmark suite,” 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, 2015, pp. 567-576.
[6] S. Song, F. Yu, A. Zeng, A. X. Chang, M. Savva and T. Funkhouser, “Semantic Scene Completion from a Single Depth Image,” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, 2017, pp. 190-198.
[7] R. B. Rusu and S. Cousins, “3D is here: Point Cloud Library (PCL),” 2011 IEEE International Conference on Robotics and Automation, Shanghai, 2011, pp. 1-4.
[8] R. Q. Charles, H. Su, M. Kaichun and L. J. Guibas, “PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation,” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, 2017, pp. 77-85.
[9] Using Kinfu Large Scale to generate a textured mesh http://www.pointclouds.org/documentation/tutorials/using_kinfu_large_scale.php
[10] B. Yang, H. Wen, S. Wang, R. Clark, A. Markham and N. Trigoni, “3D Object Reconstruction from a Single Depth View with Adversarial Learning,” 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, 2017, pp. 679-688.
[11] SmartToF http://www.smarttof.com/
{kind=link}
{kind=link}
{kind=link}
{kind=link}