
背景
数据压缩是语音信号处理的重要内容。通常的压缩先将语音转换到频域(如离散余弦变换),然后对主要频率成分进行编码,丢弃其他较小成分。这种方法虽然压缩效果好,但是丢失了一些足以影响听觉体验的频率成分,解码出来的语音存在一定程度的失真。压缩感知是一种对稀疏信号进行随机线性降采样并能近乎准确地恢复原始信号的技术。语音信号虽不够稀疏,但是可压缩,且其频谱存在特定的结构可资利用。故而我们提出利用结构特征的语音压缩感知算法。
算法:
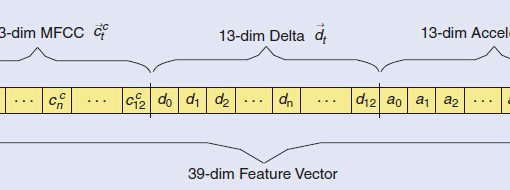
语音进行加窗修正离散余弦变换(WMDCT)得到系数矩阵,每一列为一帧语音的MDCT系数。帧内相邻MDCT系数呈连续分布状,这种特征有利于进行随机采样并高精度重建。我们用高斯混合模型表示MDCT系数的分布,每个系数由幅度和标识高斯元的状态的两个隐变量决定。帧内相邻MDCT系数的连续分布可以用幅度构成的马尔可夫过程和状态构成的马尔可夫链表示,如图右侧所示。
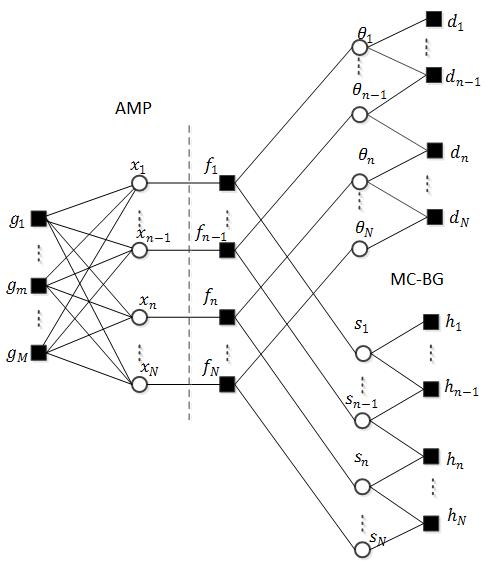
但是我们并不知道原始MDCT系数的信息,我们有的只是对原始系数进行降采样的测量值(gm)。为了从测量值中提取原始系数(xn)的信息,我们采用近似消息传递(Approximate Message Passing,AMP)算法来得到原始系数的后验信息,并将信息以和积算法的方式传递给对应的幅度(ϴn)和状态(sn)隐变量,接着在隐变量构成的马尔科夫过程和马尔可夫链上执行前向-后向消息传递。这种消息传递就是利用了帧内相邻MDCT系数呈连续分布。消息传递完成后状态和幅度隐变量将更新后的消息传递给原始MDCT系数。交替执行AMP和消息传递,直到原始MDCT系数的估值趋于稳定。
结果:
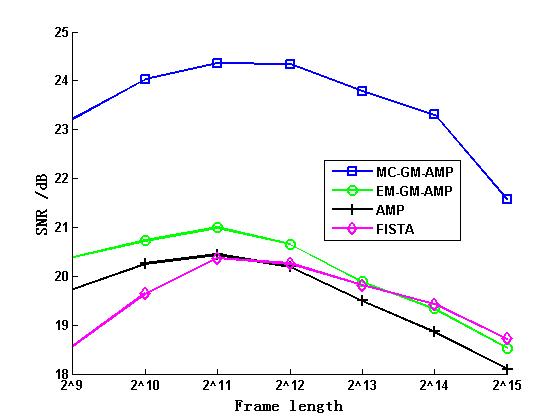
上图是我们提出的算法(蓝色)和其他几种当前主流压缩感知算法的重建信噪比,可见利用原始信号的结构信息可以显著提高重建质量。
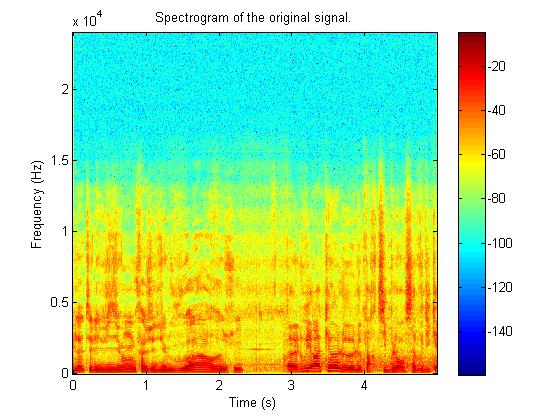
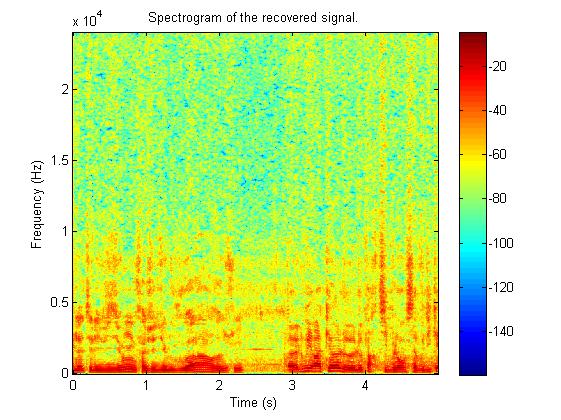
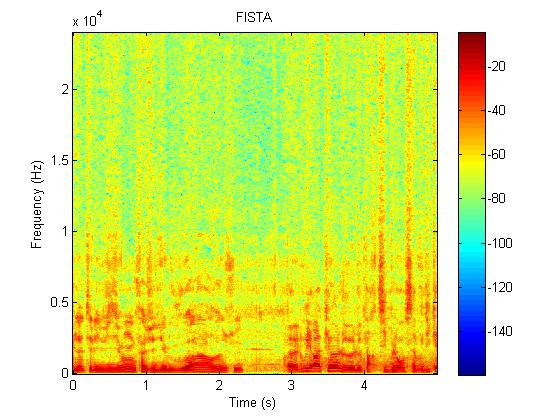
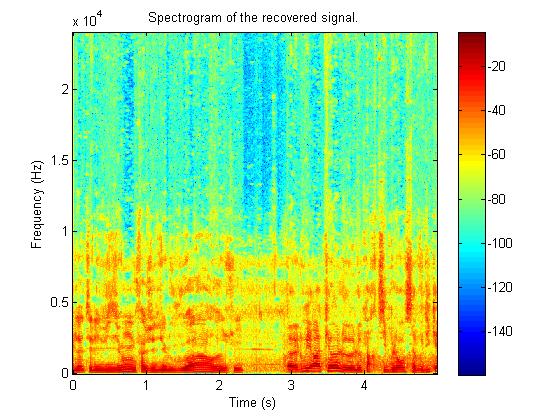
上图依次为原始语谱图,采用AMP、FISTA和我们提出的算法重建的语谱图,可见本算法可以很好地重建原始频谱,其重建系数的能量分布和原始系数最为接近。
{kind=link}
{kind=link}
{kind=link}
{kind=link}